读《置身钉内》:AI 办公里的权力、责任和人的边界
导读
原文 PDF 可以在这里下载:《置身钉内》。
这是一份 105 页的长文,作者以钉钉 ONE 项目亲历者的身份,复盘一个 AI 办公产品从立项、发布、共创、迭代到收缩的全过程。它后来被外部转述为一篇在阿里内网刷屏的长文,作者是钉钉悟空事业部 AI 产品经理滕雅辛(花名「幽素」),于 2025 年 6 月入职钉钉,是 ONE 项目较晚进入、也较晚离开的核心产品经理之一。
ONE 是无招 2025 年 4 月回归钉钉后主推的 AI 原生项目,钉钉也被重新放进阿里 AI To B 的叙事里。同年 8 月 25 日,钉钉发布 8.0 版本,有媒体称这是「AI 钉钉的 1.0」;钉钉 8.0 试图用 AI 重构工作交互、信息处理、知识搜索和应用创建方式。
陈航早年负责过阿里社交产品「来往」,后来转向企业沟通产品;2014 年,他带着几个人进入湖畔花园,后来做出钉钉。这个前史很重要:钉钉最早跑出来,靠的不是温和的协作理想,而是非常直接地回答了管理者的焦虑。
钉钉早期的企业通讯录、已读未读、DING 提醒、考勤、审批这些功能,在当时确实切中了企业管理里的触达、确认和闭环需求。「DING 一下」当时就是钉钉的重要亮点:发送方可以选择接收人、提醒时间和短信或电话等提醒方式,群聊里也可以针对未读用户再次提醒。这类能力对管理者很有吸引力,但对普通员工来说,也意味着工作边界更容易被穿透。几年后,Ding 和打卡也被放进钉钉管理功能争议里讨论,它们强化了近乎全天候可达的工作预期。
后来的竞争者也是在这之后进入同一战场。企业微信 2016 年正式亮相,开始与钉钉正面交锋;飞书国际版 Lark 则在 2019 年 3 月上线,进入企业协作市场。疫情期间,钉钉又因为在线课堂被大量学校使用而破圈,2020 年春季开学第一天约有 5000 万学生、60 万教师使用钉钉在线上课;随后钉钉又遭遇学生在应用商店集中打一星,官方甚至用视频求五星。这个事件把钉钉的组织工具属性带到了中小学生面前,也让它的负面体感被更广泛地看见。
中间钉钉也走过弯路。云钉一体之后,钉钉一度成为阿里云销售体系里的重要入口,同时也伴随着体验下滑、中小企业与个人开发者变少、付费和商业化压力上升等争议。无招 2025 年回归、ONE 被推到台前,并不是一段孤立的新故事,而是在「从管理工具跑出来、被全民远程办公和在线课堂放大、又在云钉一体和商业化里摇摆」之后,钉钉试图重新证明自己还在 AI 时代有入口价值。
这份 PDF 值得读,重点在于它把 AI 产品进入真实组织后的冲突写得很具体。全文大致可以分成八个部分:
- 「发心」讲 ONE 为什么被点燃:用户减负、AI 入口、组织战役和商业化目标如何一开始就绑在一起。
- 「定位」讲它到底为谁服务:老板还是员工,发信人还是收信人,大 DAU 还是高价值管理者。
- 「设计」讲卡片流、排序、已读、主动服务这些看似交互问题,怎样变成责任和权力问题;顾家的 PC 工作台案例也在这里暴露出产品形态和工作动作的错位。
- 「用户」讲产品进入客户现场后,碧桂园等案例如何暴露出产品叙事和真实需求之间的错位。
- 「组织节奏」讲「每日一包」、优先级队列、沉没成本和方向改元如何把不确定性压进产品、代码和团队。
- 「秩序」讲高压组织节奏怎样影响判断、健康和团队稳定性。
- 「军争」讲飞书、钉钉、Google、OpenAI、Anthropic 等 AI 办公路线之间的参照和竞争。
- 「长期」讲一个产品人如何看待项目、身体、意义感和职业判断。
这篇文章不做原文摘要,也不替钉钉写判词。它借《置身钉内》整理一套可以迁移到我们自己产品设计、开发协作和 Agent / Skill 设计里的世界观:做 AI 产品前先问清楚谁受益、谁付代价、谁被默认、谁能关闭,以及工具到底是在帮助人掌握工作,还是帮助组织更早掌握人。
AI 普及之后仍要保留选择
2025 年,正值 LLM 从 demo 走向真实工作流动荡而迅猛的上升期,能力令人兴奋,但稳定性、评测、成本、权限、商业化,每一项都尚在水面下生长。
——《置身钉内》,「发心第一」,第 10 页
AI 正在进入工作现场,这件事已经不太需要争论。Gallup 的 2026 年 workplace AI indicator 里,美国员工在工作中使用 AI 的比例已经不低:2026 年 2 月,13% 的员工每天用,28% 至少每周用几次,50% 至少一年用几次。这个数字足以说明,AI 已经越过少数技术人玩具的阶段。
同一组数据里还有另一层事实:在已经引入 AI 的组织里,65% 的员工认为 AI 对效率有正向影响,强烈同意 AI 改变组织工作方式的比例只有 12%。AI 的确在扩散,可扩散和工作重构之间还有很长一段距离;很多时候,它先变成一层叠在旧流程上的效率补丁。
我国这边,普及速度同样不能轻描淡写。CNNIC 第 57 次《中国互联网络发展状况统计报告》显示,截至 2025 年 12 月,我国生成式人工智能用户规模达 6.02 亿,较 2024 年底增长 141.7%,普及率 42.8%。AI 已经越过「技术圈先尝鲜」的阶段,大量普通用户都被 AI 产品触达过。
更早一点,CNNIC 第 55 次报告相关数据提到,截至 2024 年 12 月,我国已有 2.49 亿人使用生成式 AI;在这些用户里,45.5% 把它当办公助手。文艺创作、网络营销、软件工程等领域也已经把生成式 AI 作为日常工作工具之一,法律咨询、智慧诊疗、线上客服和智能机器人也在变得常见。放在我国语境里看,AI 同时从 App、搜索、文档、客服、教育、政务、办公助手和消费硬件渗进普通人的生活。
从移动端看,扩散更像一次 App 生态迁移。按照 QuestMobile 2026 年一季度 AI 应用洞察的数据,到 2026 年 3 月,AI 原生 App 月活已到 4.4 亿,豆包、千问、DeepSeek 位居前三;同一季度行业新增超过 1.3 亿用户。类似地,每日经济新闻转述 QuestMobile AI 产业研究院的数据也显示,2025 年 3 月移动端 AI 应用月活超过 6.47 亿,占全网 51.4%;25 个核心互联网行业里,28.4% 的 TOP20 App 已部署 AI 插件,AI 原生 App 中智能体超过 10 万个,覆盖 8 大类型和 60 多个细分场景。
政策和组织层面也在加速这件事。国务院“人工智能+”行动意见要求推动 AI 与经济社会各行业各领域深度融合,并鼓励有条件的企业把 AI 融入战略规划、组织架构和业务流程。企业里「要不要用 AI」会越来越少停留在个人偏好,更多进入组织流程、业务指标和岗位能力要求。
CNNIC 第 57 次报告还给了一个很现实的角度:截至 2025 年 12 月,网民中 13.9% 的就业人员其工作与 AI 相关,半年提升 3.1 个百分点;AI 相关人才缺口超过 500 万。报告同时提到,政务大模型已经进入内部办公、政务服务、辅助决策、城市治理等场景。这些数字放在一起,我国的 AI 普及呈现出两条线:C 端应用大规模拉新,组织、政务、教育、产业也在把 AI 写进流程。
AI 普及已经很难靠个人喜好绕开。也正因为如此,「普通人只能被动适应」这句话才更需要警惕。AI 被写进流程、指标、岗位能力和组织叙事以后,它会帮人掌握工作,也可能让人承担更多不可见的适应成本。
也正因此,我不太喜欢把这件事写成「新时代已经来临,只能适应」。这种说法有一种宿命感,像是在告诉具体的人:不管系统怎么设计,不管组织怎么压下来,你都只能跟上。可产品设计恰恰不能从这里开始。技术会扩散,组织会推动,市场会竞争,这些都是真的;但具体到一个 AI 办公产品,仍然要问它把谁的成本降下来了,又把谁的成本抬高了。
企业 AI 最容易走偏的地方,是把「适应时代」翻译成让员工适应工具。工具没做好,叫用户学 prompt;流程没想清,叫用户主动上报;成本没算清,叫员工提高 AI 使用率;稳定性没建好,叫一线用户自己判断模型有没有错。这样看起来公司很快进入 AI 时代,实际只是把转型成本分散给每个具体的人。
更好的问题应该换成这个问题:这个 AI 系统愿意保护谁。它保护管理者的确定性,还是保护使用者的掌控感;它保护平台的活跃指标,还是保护用户一天里的注意力;它保护组织对新技术的叙事,还是保护真实工作不被误判、误触和误追责。
企业 AI 当然要考虑管理者和商业化。企业软件本来就要同时服务购买者、管理者、使用者和平台自身,只是这些目标经常不同向。AI 办公产品如果不承认这种冲突,就会把冲突藏进默认值里:默认展示更多、默认触达更早、默认统计更细、默认让用户解释为什么不用。
AI 产品经理还需要补上立场感。先说清核心用户是谁,本轮最重要的收益是什么,哪些指标不能压过用户成本,哪些管理需求不能被包装成用户体验,哪些自动化必须留下人工确认和审计。没有这些,技术越强,产品越容易变成组织意志的放大器。
组织会把焦虑和变化写进产品
《置身钉内》里最反复出现的,不是某个功能做错了,而是组织把自己的压力不断塞进产品:战略要讲,英雄要回归,旧成功要延续,方向要频繁改,团队还要每天证明自己在推进。产品表面上在响应用户,实际上也在响应组织焦虑。
使命过载会让产品失去主问题
ONE 一开始就不是一个发心单纯的产品。它既想替用户减负,也想替钉钉换代;既想证明 AI 能进入工作流,也想探索商业化。
——《置身钉内》,「ONE 的发心」,第 8 页
只抓重点一个心智:当首页为空时,用户即已解除当前所有紧急重要的依赖,不再是任何人的卡点。
上了这个版本之后,在我们没有任何主动放量和宣传的情况下,产品还是保持比较温和的自然增长。比较令人惊喜的是留存,次流从 10% 出头涨到接近 30%。到 one 入口被换成悟空的 4 月份之前,次日留存涨到巅峰 45% 以上。
——《置身钉内》,「放弃大包大揽」,第 49 页
一个 AI 办公入口,表面上只是在回答用户怎么处理工作。实际进入公司以后,它常常同时承担四件事:对用户证明有用,对管理层证明效率,对公司证明战略,对外部市场证明自己没有错过 AI。每一件事都合理,但同时压到一个产品上,产品就会失去主问题。
使命过载比功能复杂更麻烦。功能复杂至少还能靠信息架构、权限、分层和流程来处理;使命过载会直接改变产品判断。用户想少打扰,管理者想更可见,平台想提 DAU,战略想要 AI 感,商业化想要入口,团队想要可汇报进展。每个方向都拉一点,最后产品会变成一个看起来什么都有、但用户不知道为什么必须用的东西。
这段比很多宏大判断都重要。它说明一个产品不一定是在功能最多、叙事最满、入口最大的时候更接近价值。相反,当它放弃大包大揽,只抓住「用户不再是别人的卡点」这个清楚心智时,用户反而更容易理解它。
AI 办公产品最难做到的事,反而是承认自己这次只解决一个核心问题。信息过载、任务管理、主动服务、知识流转、组织效率、员工成长、AI 战略和商业化入口,都可以放进长期愿景;每一轮具体设计还得回到一个小问题:这次到底帮谁少背了什么成本。
发心太多并不自动等于格局大。很多时候,发心一多,动作就会变形。既想让用户好用,既想让老板看见,既想证明组织 AI 化,既想赶上发布会,既想抢住战略窗口,产品最后就会失去节奏。每个目标看起来都不能放,最后每个目标都做不深。
AI 产品尤其容易掉进这个坑。因为 AI 这个词太大,容易让团队误以为凡事都应该 All in,凡事都可以重新包装,凡事都默认有需求。可新生事物的成长需要时间和空间,不是人有多大胆、地有多大产。运动式创新也许适合已经打明白的方法:打法明确,奏效明确,一个城市一个城市复制,一个团队一个团队推进,这时人的积极性和执行力有价值。但企业服务里的 AI 产品创新,很多场景连形态都还没想清楚,忙碌未必有效,甚至很可能帮倒忙。
这里还要补一句:AI 是工具和手段。一个旧功能被 AI 化,并不代表它创造了新价值。新体验能不能成立,要看 AI 带来的收益是否远远超过旧体验的替换成本。对企业软件来说,用户已经有流程、习惯、责任边界和组织约束;如果 AI 只带来 5% 或 10% 的局部提升,甚至只是把旧功能换了个 AI 外壳,那它很难成为从 0 到 1,只是完成了一道「把这个东西 AI 化」的命题作文。
从产品经理角度看,AI 时代的能力变化,不止体现在会写 prompt、懂模型、会拆 Agent、会看 eval。更难的是分清紧急的问题和正确的问题。紧急的问题通常来自高层反馈、发布节奏、竞品动作、客户催促、指标压力;正确的问题来自用户真实工作里的长期摩擦、信任缺口和责任成本。AI 会让紧急问题更快被实现,却不会自动把它变成正确问题。
英雄叙事很有力量,也很危险
无招身上也有这种叙事的诱惑。创立钉钉,又离开钉钉;出去折腾一圈,再被召回旧地。
不过乔布斯离开苹果以后,做了 NeXT 和 Pixar。NeXT 商业上并不耀眼,却带回了苹果后来操作系统的骨架;Pixar 则已在外部世界证明了自己。
——《置身钉内》,「内部环境:无招回归」,第 4 页
这个类比有叙事上的吸引力。创始人做出一个重要产品,又被组织结构推离,再在时代转折点被召回。这种故事天然容易让人想到「旧王归来」。
但如果只看外壳,类比会太松。
乔布斯离开苹果以后,NeXT 虽然商业上不算大成功,但留下了后来 Mac OS X 的技术地基;Pixar 则在另一个产业里证明了计算机动画的商业和创作可能。Britannica 对 Apple 历史的梳理也把 NeXTSTEP 和后来的 Mac OS X 联系在一起;乔布斯 2005 年在斯坦福演讲时,也把离开苹果后的 NeXT 和 Pixar 作为自己第二阶段的重要经历。乔布斯回到苹果时,身上带着创始人光环,也带着外部阶段积累出的技术资产、产业经验和被现实修理过的管理方式。
无招离开钉钉后的第二阶段,从公开信息看,更像一次跨境电商、消费硬件、数字零售方向的创业探索。两氢一氧官网展示的产品线包括 7sGood、HHOGene、HHOLOVE 等方向。它证明他仍然想做事,也仍有团队号召力,但很难说带回了一个类似 NeXTSTEP 或 Pixar 的硬资产。
这个类比最值得关注的地方,是组织为什么需要一个乔布斯式叙事。
当公司进入新周期,旧产品遇到新技术,一个强创始人回归,会给组织提供一种很强的精神支点:曾经能打的人回来了,旧产品还能再打一次,新入口还能被重新发明。
这种叙事有用。它能聚拢人心,压缩犹豫,制造战时状态。很多突破确实需要强意志。
它也危险。因为产品会背上超过用户问题本身的任务。ONE 除了做 AI 工作入口,还要证明钉钉没有老,证明创始人还能打,证明阿里 AI To B 有入口,证明组织重新有旗帜。产品一旦背上这些东西,就很难只回答用户到底想解决什么问题。
这里还有一个更细的差别:最初的产品创建者,未必还能在今天对这个问题说了算。创始人如果仍能重新定义问题、承担账本、决定停止条件,他才有机会按创业者的方式行动。一个人回到组织里,本质上仍然要回应集团叙事、AI 战略、发布会窗口和业绩期待,就很难自由承认「这题可能不该这么做」。
换一个强人,未必改变系统结果。只要命题仍然是「必须证明这个产品能突破 AI 应用场景」,只要产出仍然要匹配集团级期待,只要团队仍然要用工时和健康去补战略空白,结果大概率只是程度不同。努力当然重要,但有些问题根本不在努力不努力。方向、约束、账本和停止条件都错了,最后只能拼命死卷,呈现出一种非战之罪的情形。
科技创新尤其不能只靠「撸起袖子加油干」。科学、创意和产品探索,都需要方法和机制:怎样保护智力密度,怎样让高能力的人互相校准,怎样允许反对意见存在,怎样让真实反馈比面子更重要,怎样让失败及时停止而不是被包装成下一阶段。好的文化和好的结果经常互为因果,但不能只看幸存者故事,把最后跑出来的人说成天然有远见,再反过来证明所有折腾都合理。
创始人的旧胜利会留下手感。手感是资产,也是惯性。一个产品团队最难的地方,是既利用这种意志力,又不让旧胜利定义新问题。
成功会留下路径依赖
一个产品经理最难摆脱的,往往不是失败,而是成功。因为失败会留下伤口,而成功会留下手感。
——《置身钉内》,「内部环境:无招回归」,第 3 页
路径依赖最麻烦的地方,在于旧经验曾经太对。一个方法真的赢过,它就会从「当时条件下的有效解」变成团队的手感、语言和默认反应。
钉钉早期的成功就属于这种情况。2015 年的环境里,企业协作需要从微信旁边长出一套更适合组织管理的工具。老板要确认消息有没有看到,任务有没有推进,流程有没有闭环,通讯录、已读未读、DING、审批和考勤都在回答同一个问题:组织怎样获得确定性。
这套逻辑确实有效。它让钉钉有了清晰位置,也让管理者知道为什么要买、为什么要推、为什么不用微信就够了。旧环境里的有效解进入新环境后,很容易变成默认动作。
无招当然有招,而且当年那一招很有效:把管理者的焦虑产品化。老板想知道消息有没有到,就做已读未读;老板想确认员工有没有收到,就做 DING;老板想让流程往前走,就做审批;老板想管控出勤,就做考勤。这些功能不复杂,但它们在当时击中了企业管理里的确定性需求。
这一招服务的是发信人、管理者和老板的确定性,普通员工的工作质量并不在中心位置。它在 2015 年有市场,因为那时候企业需要一套「老板能用、能推、能管」的通讯工具。但到了 AI 时代,如果还沿着这套身体记忆做产品,就很容易把 AI 变成更聪明的强触达、更自动的催办、更实时的监工。
无招值得讨论的地方,不在能力有无,而在旧招曾经有效,却未必适合 AI 时代协作工具。旧招没有原罪;旧招过期以后还继续被当成新方法,问题就会出现。
到了 AI 办公场景,问题已经变成「哪些事还需要人现在注意」「哪些事可以被 Agent 接住」「什么信息应该浮上来,什么信息应该安静地沉下去」。如果还把强触达、已读、主动推到面前当成默认答案,AI 信息流就会重新长成管理工具,只是壳更新了。
旧胜利最危险的地方,是它会把条件句改写成祈使句。原本是「在 2015 年、在微信阴影下、在老板采购企业通讯工具的场景里,强确认有效」,后来会变成「协作产品就应该强确认」。这时产品经理没有在判断新问题,而是在复用旧身体记忆。
路径依赖通常从几处出现:
- 语言:团队继续用旧词描述新问题,比如入口、触达、已读、活跃、闭环。
- 指标:旧时代证明成功的数字继续决定优先级,比如 DAU、响应率、使用率、消息触达率。
- 组织:旧客户、旧销售、旧管理链路仍然更有话语权,新用户的痛感不容易进决策层。
- 系统:旧 API、旧权限、旧数据模型、旧页面和旧流程让旧方案成本更低,新方案看起来更贵。
- 身体记忆:做过成功产品的人会本能地相信当年那套手感,因为它真的帮助自己赢过。
避免路径依赖,不需要把旧东西全否掉。旧经验里有能力、客户理解、工程资产和组织动员力。更有用的做法,是把旧胜利拆成两部分:哪些是可迁移能力,哪些是旧环境产物。
做产品时,可以固定问几件事:
- 这个判断当年为什么成立。
- 当年的用户、买单者、技术条件、竞争格局和组织目标,现在还在不在。
- 这个能力是在帮助新用户完成任务,还是在维持旧管理者的安全感。
- 如果今天从零做,不继承旧系统,我们还会这么设计吗。
- 哪个小实验能证明旧经验仍然适用,或者已经失效。
做工作也一样。一个人越擅长某种旧环境,越容易把旧环境里的求生动作误认为自己的专业性。过去靠快速响应赢,就会觉得停下来想是懒;过去靠熬夜和随叫随到获得认可,就会觉得边界感是不敬业;过去靠把事情做满获得安全感,就会不敢删东西、不敢停项目、不敢说这个需求不该做。
生活里也有同样的问题。一个人在某个阶段靠讨好、忍耐、控制、证明自己、过度负责活下来,这些策略就会变成性格的一部分。环境变了以后,它们可能不再保护人,反而继续消耗人。
避免路径依赖,关键是把「我是谁」和「我曾经靠什么活下来」分开。底层能力可以保留,比如判断力、勤奋、责任感、学习能力、同理心;具体方法也要允许过期,比如随时响应、过度控制、用痛苦证明价值、把所有问题都往自己身上扛。
更实际一点,可以给自己和团队留一个定期问题:
- 现在的环境和当年相比,什么变了。
- 我们还在用哪套旧反应。
- 这套反应现在是在创造价值,还是只是在制造熟悉感。
- 下一次能不能用一个更小、更轻、更可逆的方式试试新路径。
路径依赖不可怕。可怕的是把路径当成身份,把手感当成真理,把曾经帮自己赢的东西,当成永远不需要再验证的东西。
ONE 的节奏不是单纯「快」。发布会需要新叙事,高层需要每天看见变化,团队需要证明项目还值得继续,研发和产品只能把这些压力排进当天的需求队列。于是「每日一包」变成可见变化的生产机制,优先级开始偏向能截图、能汇报、能证明战斗仍在继续的东西;方向变化也不再只是学习,而是一轮轮重新命名、重新排队、重新解释项目为什么还成立。
敏捷先回答不确定性
每日一包,本质上是一套可见变化的生产机制。
它偏爱:今天能看见的,今天能截图的,今天能被老板验收的,今天能写进 changelog 的。
——《置身钉内》,「敏捷第五」,第 69 页
每天有新包,每天有变化,每天能给高层看见,每天有问题不过夜。这当然有好处。很多团队的问题恰恰是太慢、太拖、太没有现场感。一个新项目如果完全没有这种战时响应,很可能连第一次发布都撑不到。
回到敏捷的源头,「快」从来没有单独成为目标。Agile Manifesto 的四条价值强调人和协作、可工作的软件、客户协作、响应变化;十二条原则也把客户价值、可持续节奏、技术卓越、简单性和定期反思放在一起讲。敏捷要让团队用更短周期验证更清楚的假设,减少无效消耗。Scrum Guide 也把 Scrum 放在复杂问题里讲,核心是透明、检查、适应。日报、站会和燃尽图只是形式。Daily Scrum 关注 Sprint Goal 的进展,并据此调整接下来的计划。Sprint 中可以澄清和重新协商范围,但质量不能下降;Increment 必须满足 Definition of Done,才算真的完成。
敏捷开发原本回答的是不确定性问题:需求会变、用户反馈会变、技术判断会变、市场窗口会变。与其一次性赌一个大方案,不如把假设切小,用可工作的增量尽快碰到真实反馈,再调整下一步。Martin Fowler 在 The New Methodology 里也把敏捷概括成适应变化、以人为中心,不是一套把人压进流程的加速机器。
敏捷后来被简单粗暴地概括成「快」,原因也不复杂。快最容易被看见,也最容易被考核。今天有没有包,晚上有没有截图,群里有没有进展,老板有没有看到变化,这些都能立刻进入管理视野。相反,假设有没有变清楚、反馈有没有变真实、技术债有没有减少、用户是否少走一步、团队是否还能保持判断力,都不容易当天显影。
于是敏捷就会被误读成一套可见劳动竞赛:每天都有包,每天都有汇报,每次都有新截图,每个人都很忙。表面上迭代很快,实际交付的是功能、截图和老板当天想看的变化;更难交付的认知、答案和用户持续愿意回来的理由,反而被挤到后面。
但速度会形成自己的偏好。
它偏爱当天能截图的东西,偏爱晚上能验收的东西,偏爱 changelog 里能写出来的东西。它不喜欢那些一开始不显眼、但长期决定上限的东西:个性化、反馈闭环、权限模型、审计、失败恢复、长期记忆、关系理解、评测体系。
这些地基能力很难在一天里证明自己。它们最好的状态,往往是用户用久了以后觉得顺,觉得少被打扰,觉得系统越来越懂自己,觉得出了问题也能退回来。它们不一定适合每日汇报,却决定产品能不能走远。
这对 AI 产品尤其明显。
要做重要消息排序,就要理解角色、群关系、消息语义和责任归属。要做个性化,就要有记忆、偏好和反馈闭环。要做跨系统执行,就要有权限、审计、失败恢复和长程状态管理。要做 Agent 协作,就要定义工具边界、状态传递和失败处理。
这些东西无法靠一张卡片、一句 prompt、一个入口解决。
如果团队每天都在改,却没有更接近正确问题,那不叫敏捷,只是奔波。敏捷应该让团队更快学习、更快校准、更快承认前提错了,少把时间花在给同一个错误前提打补丁上。
原文最后用「看得远,打得急」概括了这组张力。
钉钉没有看错终局。企业 AI 的核心,确实是组织上下文、工作流、权限、入口和执行闭环。
只是问题在于太早用终局叙事组织中局战斗。
钉钉看得远,也打得急。
——《置身钉内》,「总结:看得远,打得急」,第 93 页
这里的「看得远」,指的是钉钉确实看到了企业 AI 的关键资产:组织关系、权限、工作流、上下文和执行闭环。「打得急」,指的是团队过早把这个终局愿景压进每天的产品迭代里,发布会要新叙事,高层要看变化,项目要证明自己还活着,执行层就只能不断把中局问题打成当天任务。
急一点本身没有错,关键是到底在打谁。如果敌人是明确的用户痛点、真实的迁移成本、可验证的技术风险,急一点有意义;如果敌人只是老板的焦虑、发布会的叙事缺口、竞品带来的面子压力,那所谓冲锋就只是把上层的不确定性压给执行层。
很多组织喜欢用战争语言,因为它能快速压低犹豫:不要讨论那么多,先打;不要解释成本,先冲;不要问方向,先证明士气。可把产品当攻城略地、把研发当填线兵,最后只会制造消耗。没有清楚敌人、路径、边界和撤退条件的冲锋,称不上敏捷。
「运动式创新」最危险的地方也在这里。它会把创新做成一场动员:所有人都要投入,所有人都要表态,所有人都要每天证明自己站在时代这边。可创新最需要的往往是判断,服从只能保证动作一致,不能保证方向正确。团队需要有人敢说「这个场景还没想清楚」「这个需求不是用户要的」「这个阶段应该先验证,不该扩大战线」。
有效的快,发生在打法已经明确之后。比如地推、渠道复制、标准化交付、成熟流程扩张,快能换来规模优势。但在 AI 产品探索期,尤其是企业服务里的 AI 场景还没被拆清楚时,快常常只会放大混乱。它会让团队更早进入执行状态,却更晚承认问题没有被定义好。
开发者在 AI 时代会更容易遇到这个陷阱。模型能让代码生成变快,Agent 能让局部改动变快,工具能让跨文件搜索变快。快本身会让人误以为方向也对。实际上,AI 只是降低了做事的摩擦,没有自动提高判断质量。
当一个方案连续被补丁式优化时,应该停下来问一次:
- 用户抗拒的是样式,还是责任流向错了。
- 用户不点击,是入口不明显,还是这个入口根本不该出现。
- 模型输出不稳定,是 prompt 不够好,还是产品把高风险判断交给了不该自动化的环节。
- 每天都有变化,是更接近用户,还是更接近汇报。
这些问题不一定让项目变慢。很多时候,早点问,反而能少走很多路。
如果老板的事情必须当天结清,现实里也能做。组织总会有高优先级反馈、发布窗口、关键客户、线上风险和战略表达。关键是,「当天结清」要结清什么。
更健康的结清方式,是当天结清响应和决策不确定性,不要强行结清所有产品和工程问题。当天应该给出:现在判断是什么,能交付的最小安全动作是什么,不能当天完成的根因是什么,短期方案会留下什么债,长期方案排到哪里,下一次用什么证据判断它有没有变好。
这可以拆成两本账:
- 短期响应账:回答今天必须让谁放心。线上风险有没有止血,老板关心的问题有没有解释,关键客户有没有兜住,发布会材料有没有可展示版本。短期响应可以很快,但要尽量可回滚、可开关、可标记临时方案,不要把临时补丁伪装成长期架构。
- 长期沉淀账:回答产品和系统是不是更接近正确问题。这个补丁暴露了哪类地基能力缺失,下一步要补权限、审计、反馈、评测、个性化还是工具契约,谁负责把临时方案移除或转正,什么信号说明这个方向应该停止。
短期和长期不必二选一。成熟团队可以当天响应,但不会让当天响应吃掉所有未来。它会把「今天先稳住」和「下个周期补根因」写在同一张账上。今天交最小安全增量,明天补验证和清理;今天给老板看得到的变化,也要给团队留下能继续走的地基。
可汇报的东西,常常长得很像进展:多了入口,改了样式,补了规则,修了文案,上了一个新卡片。可沉淀的东西未必热闹。
——《置身钉内》,「敏捷第五」,第 75 页
开发速度最容易误导人的地方就在这里。它让组织每天都能看到收入,却不一定看到隐债。一个系统是不是越来越稳,一个入口是不是越来越懂用户,一个 Agent 是不是越来越知道什么时候不该做,这些都不如「今天又改了什么」显眼。
组织的优先级队列会写进代码
这不是简单的开发速度问题。钉钉很快。ONE 也很快。问题在于,跑得很快以后,谁来决定方向;每天都有交付以后,什么会被做深,什么会被挤掉。
——《置身钉内》,「敏捷第五」,第 68 页
敏捷从来不是抽象的。组织总是对某些人、某些事、某些信号更敏捷。
——《置身钉内》,「敏捷第五」,第 69 页
ONE 的问题更像几套优先级同时拉扯同一个项目:用户要不要用,老板看不看得见,集团 AI 战略能不能讲,发布会能不能交,团队当天能不能进包。单一产品经理的判断、单一设计形态的选择,已经解释不了这个局面。
这已经超出传统意义上的「需求优先级」,更接近组织事实上的问题单系统。某个人看见的问题,会立刻进入最高优先级;某个截图、某个吐槽、某个竞品动作,会获得超出它本身的权重;而那些用户反复需要、但不适合当天验收的东西,会长期留在重要不紧急里。
这种机制对开发的影响非常具体。
它会改变中断模式。早上一个问题,下午一个方案,晚上一个包,工程师和产品的注意力会被切成很多短片段。它会改变技术债的形状。代码里最容易留下的,往往是那些大家知道应该深做、当时却没有时间深做的东西。它还会改变团队对完成的理解:能被看见、能被截图、能被验收,越来越像完成;能长期复用、能让用户少烦、能让系统少错,反而不容易被记账。
「老板是不是最大用户」这个问题因此很尖锐。高权重用户往往自带人工个性化:有人解释,有人兜底,有人响应,有人把他的模糊感受翻译成需求。普通用户没有这些。他看到的就是默认规则、入口、卡片、已读、排序、关闭不了的模块。
更残酷一点说,如果顶层带头人最强烈的需求是「证明我还能打一仗」,那这件事也会写进代码。团队会自然偏向能证明战斗正在发生的东西:新入口、新标识、新卡片、新发布、新包、新汇报。至于这个方向是否用户需要,旧场域里的问题有没有被重新拆清,反而容易排在后面。
这时 ONE 除了产品身份,也成了组织焦虑的容器。它要证明钉钉没有老,要证明 AI 战略有入口,要证明带头人重回战场仍有号召力,要证明团队每天都在推进。一个产品背这么多证明任务,当然会越来越难说出那句最朴素的话:这个东西到底帮用户少做了什么?
如果一个产品主要围绕高权重用户的反馈循环优化,它会越来越适合被汇报,而不一定越来越适合被普通人日常使用。
对开发者来说,这个提醒很现实。很多技术决策没有输在架构会上,而是输在优先级队列里。权限模型、反馈闭环、长期记忆、可观测性、失败恢复、灰度、回滚、审计、个性化,这些东西都知道重要,但它们很难在当天形成可展示变化,于是就不断被挤到后面。
大公司不一定比小公司更能做创新,原因也在这里。大公司在砸钱、砸人、拿资源、补短板、做规模复制上当然有优势;但当问题还没有被定义清楚,当结果无法在一天内变成阶段性业绩,当重要事情很难被拿到台面上表演,大公司反而会天然吃亏。人越多,每个人越需要证明自己有产出;层级越多,越容易把「能被看见的表现」误认为「有效动作」。
小团队的优势不在浪漫,而在低沟通成本、低生存成本和更高比例的有效动作。一个十人以内的小队,如果切在足够具体的真实场景里,可以先安静地把事情做深,直到某一天突然进入更大视野。大团队则更容易一上来就背负过高期待:战略要讲,发布要赶,老板要看,组织要证明,最后还没找到普通用户愿意用的理由,资源和人已经被拉满。
项目会保护自己
无论是做 AI 产品验证 idea,做其他产品,或者泛化为做一切实验假设,一旦立了项,或做出了某种初步假设,沉没成本就会让这个产品或者实验假设的发起人,下意识成为自己假设的拥趸。一个人提出一个念头,很快就会开始保护这个念头;一个团队做出一个形态,很快就会开始解释这个形态;一个组织投入了资源、时间、排期、汇报链路,就更难承认:也许一开始题就没问对。
大型组织的沉没成本更高,因而更容易陷入自恋、自我解释和难以掉头。
——《置身钉内》,「用户第四」,第 55 页
这其实是很典型的大公司病。
在大公司里,团队一边解决用户问题,一边证明自己有存在价值。一个团队怎么证明自己值得继续拿资源、继续保留编制、继续出现在组织地图上?说「我们想清楚了,暂时不该做」很难形成组织信用;项目、排期、方案、里程碑、周报、发布节奏和可见产物更容易被当成证据。
于是项目本身会开始获得生命。它一旦立项,那个等待验证的假设就会长出一组人的工作来源、一条汇报链路、一批排期承诺、一套组织期待。承认它可能没必要,除了要承认一个想法错了,还像是在承认这段时间的会议、文档、代码、设计稿、加班和管理注意力都没有换来足够价值。
这时候,团队自然会倾向于保护它。
用户不用,可能解释成入口不明显;用户抗拒,可能解释成教育成本还不够;数据不好,可能解释成样本不足;没有真实场景,可能继续做泛化能力;客户不买单,可能继续做品牌表达。每一个解释单独看都可能有道理,但它们叠在一起,就会把一个本该被证伪的假设,慢慢养成一个需要长期供养的产品。
更麻烦的是,这种产品常常会有一些产出。它会有页面,有文档,有 demo,有埋点,有看板,有发布记录,有用户访谈纪要,也会有一些正向反馈。正因为它不是零,组织更难停止。停止一个完全失败的东西容易,停止一个看起来「有点东西、再给一点时间也许能成」的东西很难。
「创造没人用的产品」背后常常是这套组织逻辑。它未必来自某个团队故意欺骗上级,而是来自每一层都需要证明自己在做事。团队需要证明自己有价值,管理者需要证明方向在推进,部门需要证明战略有落点,公司需要证明自己没有错过时代。最后,用户问题反而变成这些证明材料里的一个字段。
很多组织问题会被增长遮住。系统还在增长时,每个人都能从中受益,问题就显得可以忍:流程重一点没关系,汇报多一点没关系,方向摇一点也没关系,反正蛋糕还在变大。等增长停下来,问题才会暴露,因为这时组织已经不能再靠外部增量消化内部低效,只能开始争夺存量注意力、存量预算和存量功劳。
这时动作就更容易变形。未必是所有人突然变坏,更多是系统训练出了一套防御行为:做能看见的事,避开难证明的事;做能当天汇报的事,放下长期见效的事;做能服务高权重反馈的事,搁置普通用户需要但说不出来的事。项目会保护自己,组织也会保护让项目继续存在的解释。
AI 会让这种病更严重。因为 AI 能更快生产证明材料:更快的原型,更快的文案,更快的竞品分析,更快的测试用例,更快的周报,更快的 demo。以前一个没人用的产品至少要花一段时间才显得完整,现在它可以很快拥有完整外观。它越完整,就越像值得继续投入;越继续投入,就越难承认前提错了。
健康的产品组织必须给停止留制度位置。项目不必全都包装成阶段性胜利。有些项目最有价值的产出,就是证明一个方向不该继续;有些团队最有价值的判断,就是及时告诉组织:这个问题不值得用产品解决,或者现在不是这个形态。
如果一个团队只有通过不断立项、不断上线、不断制造可见产物才能证明自己有价值,它就会天然抗拒证伪。成熟团队也应该能因为正确地停掉一个坏假设而获得信用。
方向变化会成为常态,也要付成本
无招回归后,每次发布会都像一次改元。一个 logo 像一个年号:从魔法棒,到 ONE 的太极标,再到悟空猴头。一朝天子一朝臣,每换一次符号,就重讲一遍故事。
钉钉像改元,飞书像验货。钉钉在台上给组织换年号,飞书把电脑摆出来让用户看能不能跑。
——《置身钉内》,「发布会里的机锋」,第 88-89 页
中国历史上,最爱改元的皇帝之一是武则天。她在位时间并不算长,却频繁更换年号。每一次改元,往往都对应一次祥瑞、一场政治转折、一次合法性宣示,或一次对佛教、道教、天命符号的重新调用。
年号在她那里,不只是纪年,也是政治自我命名。可改元太频繁,也会让时间本身失去稳定感。
——《置身钉内》,「总结:看得远,打得急」,第 93 页
原文把钉钉的发布会和方向变化写成「改元」,写的是组织每次都要重新相信一套叙事,命名变化只是表层。这个比喻在原文里出现了两次:第一次用来对比钉钉和飞书的发布会风格,第二次明确落到「武则天改元」。
具体说,钉钉这条线不是只换了一次名字。无招回归后,团队先经历了「魔法棒」式的 AI 助手想象,接着把 ONE 推成带太极标的新入口,再到发布会上换成悟空猴头,最后 ONE 入口又被换成悟空,实际并入下一轮叙事里。四次变化看起来是 logo、入口和命名变化,落到团队身上,就是目标、解释、汇报口径和用户心智不断重开。
原文也替改元留了一句体面解释:大组织需要旗帜、阶段感,也需要让内部知道「现在打哪一仗」。这句话当然成立,但只能成立一半。
健康的旗帜应该回答四件事:敌人是谁,先打哪里,什么算赢,什么时候停。如果旗帜只回答「我们又换了一个时代叙事」,却不回答真实用户问题、执行路径、资源代价和停止条件,它就更像合法性仪式,离战略坐标很远。它让内部知道的也不再是打哪一仗,而是现在该围绕哪面旗帜重新表忠心。
这个比喻准确在于,方向一改,表面上只是换了目标、换了叙事、换了优先级,实际被摧毁的是组织已经积累的认知资产。
一个团队做过一轮产品,会留下很多隐性积累:对用户场景的理解,对边界条件的判断,对技术可行性的评估,对数据表现的经验,对错误路径的排除,对协作方式的磨合。这些东西不一定都写在文档里,但它们是项目核心资产。
如果方向频繁变化,每次都重新定义目标、重新包装叙事、重新调整优先级,上一轮积累的大量认知就会被迫作废。组织看起来在变快,实际上在变慢,因为团队没有向前迭代,只是在不断重开地图。
AI 能力边界一直在外扩
为什么这种变化会成为常态?管理者喜欢折腾当然是一部分原因,但外部世界也确实进入了高波动周期,AI 的能力边界变化太快了。
这条线要看的是能力边界怎样一路外扩:从「机器能赢人」到「机器能生成」,再到「机器能进入真实工作流做事」。截至 2026 年 6 月回头看,过去十年大概是这样走的。
2016 年
- 3 月:Google DeepMind 的 AlphaGo4:1 战胜李世石,很多普通人第一次把 AI 记成一个真实时代事件。那时 AI 的公共想象还是「在封闭规则里超过人类专家」。
2017 年
- 6 月:论文 Attention Is All You Need 提出 Transformer。它当时不是大众事件,但后来成为大模型、长上下文、多模态和 coding agent 的共同底座。
2020 年
2022 年
- 4 月:DALL·E 2 让文生图进入大众创作,AI 不再只是回答问题,也开始生产可以被分享、传播和改造的视觉内容。
- 6 月:GitHub Copilot 面向所有开发者开放,AI 开始进入 IDE 和日常编码。它还不是今天意义上的 Agent,但已经改变了软件开发里「谁先写第一版」的感觉。
- 8 月:Stable Diffusion 公开发布,开源文生图开始进入大众创作和社区改造。
- 11 月:ChatGPT 发布,把聊天变成普通人接触 AI 的默认入口。很多人对 AI 的认知,也是在这里从「技术新闻」变成「每天能用的工具」。
2023 年
- 3 月:GPT-4 让复杂推理、代码和图像输入进入主流讨论。
- 9 月:ChatGPT 逐步补上看、听、说这类多模态交互,AI 产品开始从文本框走向更自然的输入输出。
- 11 月:GPTs 发布,可定制助理把「模型 + 工具 + 知识 + 任务」的组合推到普通用户面前。
- 全年:中国进入「百模大战」。百度、阿里、字节、腾讯、智谱、MiniMax、月之暗面、百川智能都在抢入口、抢模型、抢备案和抢人才。这里最值得记住的是节奏:阿里的通义千问后来延展成 Qwen 开源生态;月之暗面的 Kimi 把长文本心智打进大众用户;王小川的百川智能成立不久就推出 Baichuan-7B,曾经是国产开源模型讨论里的高频名字;王慧文的光年之外则在成立数月后被美团收购,说明 AI 创业在那个阶段既有巨大动员力,也有极强的不确定性。
2024 年
- 2 月:Gemini 1.5 把长上下文推到百万 token 量级,Sora 又把文本到视频拉进大众视野。AI 开始处理更长的材料、更复杂的媒体和更强的世界建模想象,单轮问答不再是主叙事。
- 4 月:Llama 3 让开源模型生态继续逼近闭源模型的主流能力区间。开源模型不再停留在「能跑」阶段,开始不断逼近主流产品能力。
- 5 月:GPT-4o 把实时语音、视觉和文本放到同一个交互模型里。AI 的交互开始更接近实时陪伴、翻译、看图讲解和现场协作。
- 5 月:字节通过火山引擎正式发布豆包大模型家族,把模型能力、低价 API、扣子、MarsCode 和后续 TRAE 这类开发工具串到一起。豆包的意义在于,大厂开始把 AI 从聊天入口、云服务、开发工具、内容生态一起铺开。
- 9 月:o1 把「模型愿意花时间推理」变成新的产品心智。AI 开始在数学、代码和复杂问题里显式强调深度思考,而不只追求更快回答。
- 10 月:Anthropic 发布 computer use,让 Claude 能按屏幕截图操作电脑。到这里,AI 的问题已经从「能不能回答」开始移向「能不能操作环境」。
- 11 月:Windsurf 正式发布,把「AI-first IDE」和「agentic IDE」的说法推到开发者面前。它和 Cursor 的竞争,让 AI 编程从补全插件变成新的开发环境之争。
- 12 月:Google 用 Gemini 2.0 把「agentic era」写到发布标题里,浏览器操作、工具调用和多模态输出开始连成一条线。
2025 年
- 1 月:DeepSeek-R1 把推理模型、开源权重和成本叙事一起推到台前。它对大众的冲击包括两层:「中国模型变强了」,以及「强能力是否一定要巨额闭源成本」这个问题被重新打开。
- 1 月:OpenAI 发布 Operator,把网页任务交给 Agent。AI 从「回答」继续往「替你跑一段流程」移动。
- 2 月:deep research 把多步资料搜索、阅读和整理变成产品能力。
- 2 月:Karpathy 带火 vibe coding 这个说法。这个词一开始有点玩笑感,但它准确抓住了一个变化:越来越多人先描述目标,让 AI 生成第一版,再靠运行、观察和反馈往下推,写软件的起点不再总是语法和框架。
- 3 月:Manus 以通用 AI Agent 的姿态进入大众视野。无论它后来表现如何,它都让更多普通用户第一次认真想象「一个 Agent 可以跨工具替我完成一段真实工作」。
- 3 月:OpenAI 推出 GPT-4o 图像生成,很快带动了社交平台上的吉卜力风格头像潮。
- 4 月:阿里开源 Qwen3,把混合推理模式、开源权重、Agent 能力和多语言覆盖一起推进。通义千问从「国产大模型产品」变成了很多开发者会真实下载、蒸馏、部署和接 API 的模型家族。
- 5 月:Anthropic 宣布 Claude Code generally available,coding agent 从「能帮忙写代码」快速推进到更深介入开发流程的工具。
- 5 月:OpenAI 发布 Codex research preview,把 coding agent 接进云端开发和代码任务执行。
- 6 月:Cursor 发布 1.0,把 Bugbot、Background Agent 和 MCP 安装也一起推给开发者。
- 8 月:Google 在 Gemini 里发布 Nano Banana 图像编辑升级,重点变成角色一致性、多轮编辑和照片融合。图像能力从「生成一张图」走向「保留主体、连续修改、变成工作流」。
- 10 月:OpenAI 宣布 Codex generally available,并把它接入 CLI、IDE、云端、Slack 和 SDK。
- 下半年:AI 编程进入Coding Plan心智。Claude Code 可以接入 Claude Pro / Max 订阅,Codex 也被放进 ChatGPT 各档计划里,用户开始形成一种新心智:每月买一个 plan,就能获得持续可用的编程 Agent。
2026 年
- 1 月:Cursor 在 Scaling long-running autonomous coding 里记录了一个浏览器实验:数百个 Agent 在接近一周的时间里协作,写出超过 100 万行代码和 1000 个文件,目标是从零实现浏览器。这个实验争议很大,The Register 就直说它更像是在证明 AI 可以大规模写出质量参差的代码;但它仍然说明一件事:Agent 已经开始能承接过去只有团队才会尝试的长程重工程。
- 1 月:Kimi K2.5 和 Kimi Code 发布,国内模型厂商继续把 coding agent 当成关键入口推进。
- 2 月:Anthropic 的 Nicholas Carlini 用 16 个 Claude Opus 4.6 Agent 做了一个 C 编译器实验。项目跑了近 2000 个 Claude Code session,花费约 2 万美元 API 成本,产出约 10 万行 Rust 编译器代码,可以构建 Linux 6.9,也能编译运行 Doom;但原文也明确写到它还不是可替代真实编译器的成品,生成代码效率不高,部分环节还依赖 GCC。这类案例的重点在于,AI 开始能在测试、反馈、任务分解和长程运行环境里啃大活,并没有宣告编译器工程师已经被替代。
- 2 月:Cursor 让 cloud agents 拥有自己的远程电脑,开发现场进一步变成模型、CLI、IDE、远程环境、浏览器、测试和评审工具的组合。
- 春季:阿里云百炼、智谱 GLM、MiniMax、Kimi 等都围绕 coding / token plan、专用 endpoint 和兼容 Claude Code、Codex、Cursor、Cline、OpenClaw 的工具链做文章。
- 春季:Coding Plan 的低价补贴开始退潮。阿里云官方文档里,Coding Plan Pro 是 $50/month,推荐模型直接包括 qwen、kimi、glm 和 MiniMax;同一页也写明 Lite 版从 2026 年 3 月 20 日起不再接受新订阅,后来 Qwen Cloud 文档已经明确写着 Coding Plan is being deprecated,迁移方向变成按 credits 计费的 Token Plan。
- 4 月:OpenAI 发布 GPT-5.5 并明确把它放进 ChatGPT 和 Codex。
- 上半年:以 OpenClaw 为代表的「龙虾」式个人 Agent 也在社区里进入大众视野。它重要的地方不在某个项目到底能火多久,而在个人开始把邮箱、消息、日历、网页、代码、文件系统和语音都接进一个本地或半本地 Agent,这同时带来效率想象和安全焦虑。
把这条线放在一起看,「2025 年之前 AI 被认为问答为主」只是普通用户对主入口的感受,无法概括能力研究本身。AI 早就从棋类、科学、图像、代码一路往外扩;只是到 2025 年之后,Agent、图像编辑、深度研究、浏览器操作、代码仓库操作、个人电脑操作、长程重工程、coding plan 成本模型和企业办公系统同时变成可用产品,才让这种变化砸进更多人的日常工作。
这里要单独看 coding agent 和 coding plan 这条支线。浏览器和编译器实验说明,AI 开始从「写一段代码」推进到「在脚手架、测试和反馈循环里连续啃重活」;coding plan 的退潮则说明,重活背后一定有真实成本。当 OpenClaw / 龙虾这类个人 Agent 让更多非程序员也开始把 coding plan 当成通用算力入口,固定月费很快就会撞上推理成本。到这一步,AI 的变化已经不只发生在产品界面里,也发生在云厂商的账本里。
这已经超出单个功能变快的范围。底层能力图谱在变,产品方向自然会被不断重估:入口要不要改,能力要不要接,老流程要不要重写,商业化叙事要不要换。
变化要配置化,也要保留不变量
但「变化成为常态」不等于「拥抱变化」可以被无限拔高。拥抱变化本来应该意味着:当真实用户、真实技术约束、真实成本结构发生变化时,团队愿意更新判断。它不应该变成:上层没有想清楚,执行层每天消化;竞品发了截图,团队马上改方向;战略词变了,产品重新命名;老板感受变了,所有人重新补材料。
有证据的变化,是学习。没有证据的变化,是摇摆。前者让组织越来越聪明,后者会训练出一种很糟糕的行为:大家不再相信当前方向。产品不敢做长期设计,研发不敢做基础建设,运营不敢做深度用户验证,所有人都在等下一次风向变化。需求变更成为所有人的梦魇,伴随着一次次认知覆盖。
不要写死的重要性也在这里。它已经超出一句代码口头禅,更像一种产品和组织的生存策略:承认世界会变,但不要让每次变化都把系统连根拔起。
从产品和工程层看,灵活配置化确实是必要的。Feature flag、灰度配置、远程开关、规则引擎、实验平台、模型路由、prompt 版本、个性化策略、权限策略、文案配置、排序权重、入口开关,这些东西都是为了让产品在不重新发版、不大规模返工的情况下调整行为。Martin Fowler 网站上的 Feature Toggles 文章也把它称为一种能帮助团队更快且更安全交付功能的模式。
设计模式里也有同一层思想:找出会变化的东西,把它封装起来。O’Reilly 对 GoF 设计模式的解读里专门提到 Find What Is Varying and Encapsulate It:不要只问什么变化会迫使重做设计,而要问什么东西希望以后能变而不需要重做设计。
这句话放到 AI 产品里也成立。要分清哪些东西应该稳定,哪些东西应该允许变化。
稳定的东西应该是:用户真实任务、责任边界、数据契约、权限模型、审计日志、回滚路径、人工接管、风险分层、可观测性和核心领域模型。它们是产品地基,不能因为今天要讲「AI 入口」,明天要讲「主动服务」,后天要讲「一人公司」就跟着频繁改。
可变的东西应该是:入口位置、卡片密度、排序权重、模型选择、prompt 版本、文案表达、灰度范围、策略阈值、默认开关、推荐强度和实验分组。它们应该被配置、被版本化、被观测、被回滚。
一个更健康的 AI 产品结构,应该像三层。
底层是稳定能力:清楚的工具契约、领域对象、权限和审计。它回答「系统能安全地做什么」。
中间是策略配置:规则、模型、prompt、排序、阈值、灰度和开关。它回答「在什么条件下怎么做」。
上层是体验实验:入口、卡片、文案、交互路径和展示方式。它回答「这次怎样让用户更容易用」。
方向可以变,但最好主要变在上层和中层;底层不能每次都推倒重来。如果每次改方向都要重做核心对象、权限链路、数据结构和审计方式,说明变化没有被隔离,组织是在用人的注意力和开发时间替架构还债。
当然,配置化也有边界。很多团队听到「不要写死」,最后会把所有东西都做成配置,得到一个更难理解、更难测试、更难删除的隐形系统。配置本身也会变成债:没人知道哪个开关还在用,哪个规则覆盖哪个规则,哪个实验已经结束,哪个灰度其实早该转正或删除。
配置化必须配套几条纪律:每个配置有 owner,有生效范围,有默认值,有日志,有回滚,有过期时间,有删除机制。短期开关按短期债管理;实验配置服务学习,不能变成永远逃避产品判断的挡箭牌。
普通人要看退潮后留下什么
再往上一层看,普通人面对的是整个技术叙事的循环,范围超过单个产品变化。低代码、区块链、元宇宙、AR / VR、O2O、共享经济,都经历过突然爆火、快速扩张、资本和媒体集中关注,然后有的冷下来,有的变成基础设施的一部分,有的只留下少数真实场景。Gartner Hype Cycle 描述的就是这种节奏:技术突破带来媒体关注和早期故事,随后进入过高预期、失望低谷,再到适用场景逐渐清晰。Gartner 在 2024 年的新兴技术 Hype Cycle 里也提到,生成式 AI 已经从基础模型兴奋转向更关注 ROI 的使用场景,同时 autonomous AI、开发者生产力和人机安全成为新焦点。
这条曲线不支持两个极端结论:一边把所有概念都当骗局,一边把所有浪潮都当机会。大概念会被市场讲得过满,但其中可能有一部分真实能力会留下。普通人更该训练的是区分「叙事热度」和「真实成本变化」,少在每波浪潮里 all in,也少把每波浪潮都当笑话看。
判断一个新概念,可以问几件事。
- 它到底降低了哪种成本:信息成本、生成成本、交易成本、协作成本、部署成本,还是只是降低了讲故事的成本。
- 它改变了谁的能力边界:普通人、专业人员、管理者、平台方、供应商,还是只让原有强者更强。
- 它有没有真实付费、真实迁移、真实留存、真实复用,还是只有 demo、融资、发布会和截图。
- 它退潮以后,会留下什么基础设施、工作方法、技能迁移或行业标准。
- 它要求个人投入的是可迁移能力,还是只能绑定某个平台、某个概念、某个短期红利。
普通人最稳的策略,是建立一组抗变能力:理解真实问题的能力,拆流程的能力,写清楚的能力,用工具验证的能力,判断风险的能力,和把经验沉淀成可复用资产的能力。工具会换,热点会换,模型会换,但这些能力会在每一轮变化里复利。
同时也要给自己留一点试错预算。完全不碰新东西,会错过真实变化;每次都扑进去,会被叙事拖着跑。更好的方式是:小成本试用,记录真实收益,保留可迁移经验,避免把身份押在某个短期概念上。
AI 时代最现实的心态也许就是这样:变化会越来越快,我们很难控制外部风向。但我们可以控制三件事:不要把所有东西写死;不要把所有变化都当成真理;不要把自己变成热点的耗材。
产品要能抗变,人也要能抗变。值得拥抱的是被证据推动的变化、能留下资产的变化、不会反复清零人的变化;变化本身不值得被当成信仰。
时间很微妙:腾讯在讲另一套 AI 下半场
几乎在《置身钉内》被大量讨论的同时,隔壁腾讯也发生了一件很有意思的事:2026 年 6 月 5 日,汤道生和姚顺雨在腾讯云 AI 产业应用大会上做了一场公开对谈,主题同样是 AI 下半场、Agent、Context 和企业场景。
先说姚顺雨。他的履历本身就很能说明问题:高中拿过 2014 年 NOI 银牌,高考 704 分进入清华姚班,后来到普林斯顿读博,研究过 Tree of Thoughts 和 ReAct;毕业后进入 OpenAI,参与 Operator 和 Deep Research,之后加入腾讯负责混元大模型和 AI Infra。每日经济新闻用了一个很醒目的角度:「70 后」汤道生和「95 后」姚顺雨同台。这个背景会影响他看问题的方式:他不是从十年前企业通讯工具的胜利手感出发,而是从模型、Agent、真实场景、评估和产品闭环出发。
在这场公开对谈里,姚顺雨谈到 AI 下半场时,重点不是模型参数,而是 good problems、environments 和 context;他也提到选择腾讯,是因为腾讯有大量真实产品场景和上下文。这个视角很年轻,也很前沿:它不急着先给旧产品换一个 AI 入口,而是先问真实问题在哪里、模型怎么进入场景、反馈如何回到产品和评估里。
这里需要先打个补丁:这不是拿腾讯踩阿里。腾讯这场是高层公开战略表达,《置身钉内》是一线产品参与者的项目复盘;一个讲愿景和方法论,一个讲具体项目里的伤口和账本,两者不能完全对应。把它们放在一起,只是为了看同一时间点里,两个大厂面对 AI 时使用的语言、组织包袱和行动方式有什么差异。

这个时间点很微妙。阿里这边,我们读到的是一个内部项目参与者写出的高压现场:发心过载、产品定位摇摆、每日一包、发布会改元、组织焦虑和人的消耗。腾讯这边,公开场合讲的是另一套关键词:找真实问题、Context、模型产品共设计、真实世界反馈、长期游戏。
只看对谈会不够。更有意思的是,腾讯这段时间确实也在密集做产品。
- 2024 年 5 月,腾讯元宝正式上线。它是腾讯基于混元大模型推出的 C 端 AI 助手,核心能力是 AI 搜索、总结、写作、长文档解析和个人智能体。到 2026 年一季度,QuestMobile 的数据里,元宝已经和豆包、千问、DeepSeek 一起进入头部 AI 原生 App 讨论;春节流量高峰后,元宝 DAU 仍维持在约 900 万。
- 2026 年 3 月,WorkBuddy 正式上线。它走的是「腾讯版龙虾」路线:兼容 OpenClaw 技能,可通过企业微信远程操控,也能接 QQ、飞书、钉钉等工具,还支持多窗口、多 Agent 并行。
- 2026 年 3 月 22 日,微信 ClawBot 插件推出,支持把 OpenClaw 接入微信。用户通过扫码或复制命令,把个人 Agent 放进微信聊天入口里调用。
- 2026 年 4 月,腾讯又推出 QClaw 国际 beta,官方说法是基于 OpenClaw,把安装、配置和启动门槛降下来,让不懂复杂部署的用户也能养自己的 Agent。
- 到 2026 年 6 月这场大会,腾讯的效率智能体工具集已经包括 QClaw、WorkBuddy、元宝、ima、腾讯文档;新发布的 WorkBuddy Enterprise 和办公智能体套件,又把腾讯文档、腾讯会议、腾讯乐享、CodeBuddy、ClawPro、ADP 串成企业 Agent 基础设施。
腾讯并没有只停在「Context 很重要」这句话上,它的动作也确实围绕 Context 展开:C 端的元宝和微信承担用户入口,个人端的 QClaw / ClawBot 让 Agent 进入熟悉的聊天窗口,办公端的 WorkBuddy 和 Agent Suite 连接企业知识、文档、会议、开发、权限和治理,研发端的 CodeBuddy 则覆盖插件、IDE 和 CLI 里的 coding agent 场景。
这条路不一定天然更善良,也不一定天然更成功。微信入口越强,权限、隐私、误操作、规模化算力和监管压力也越强;企业 Agent 越深入,管理后台、审计、角色隔离和用量统计越容易滑向新的管控系统。腾讯同样会遇到大厂病,甚至它的生态优势本身就可能变成新的锁定和新的依赖。
但它和钉钉 ONE 的对照仍然很清楚:钉钉试图把消息、日程、待办、审批重新组织成一个 AI 原生工作信息流,让「人找事」变成「事找人」;腾讯这套公开叙事和产品动作,则更像是把 AI 分散铺进已有高频场景,让模型、工具、知识、身份、权限和业务系统形成多个入口、多条闭环。
一个是把旧办公系统改造成一个新入口,一个是让 AI 渗进已有入口和基础设施。前者的风险是宏大叙事压过真实问题,后者的风险是生态惯性压过用户边界。
姚顺雨在对谈里讲到,方法论成熟之后,更困难的是寻找好的问题。这个判断和《置身钉内》里反复出现的问题其实对得上。ONE 有方法,也能执行;它有钉钉的组织上下文,有消息、日程、审批、会议、文档,也有强执行团队。问题恰恰在于:这些能力被拉去证明一个宏大入口时,团队没有足够空间重新定义「到底什么问题值得做」。
腾讯对 Context 的说法也值得对照。Context 不等于把数据都塞给模型,它是产品能力、工程能力和组织协同能力的综合体。钉钉当然有很强的 Context,但旧 Context 里也包含旧权力结构:发信人、已读、DING、审批、组织架构、强触达。AI 拿到这些上下文以后,不会自动变成用户秘书;它可能先继承旧系统的立场。Context 设计还要追问:模型看见更多以后,站在谁那边。
Co-Design 也是一个重要对照。腾讯这套公开表达里,模型团队、产品团队和真实反馈必须一起看,AI 产品不能先写完需求再丢给模型团队实现。模型能力会改变产品边界,产品数据会反过来改变模型评估,用户反馈又会改变什么叫好结果。相比之下,ONE 的悲剧发生在模型和产品之间,也发生在产品、组织、发布会、管理意志和用户痛感之间:这些东西没有被放在同一张桌子上诚实对齐。
还有一个更现实的点:腾讯讨论 Token 性价比时,看的是任务闭环总成本,token 单价只是其中一项。这个视角放回 ONE,也很有启发。一个 AI 卡片如果节省了用户点进会话的一秒,却让用户多花十秒判断自己是否会被已读追责,这笔账就算不过来。一个模型如果便宜但经常需要人解释、确认、补救、兜底,便宜也只是表面价格。企业 AI 的成本不只包括 token,也包括人的注意力、信任、心理缓冲和失败后的解释成本。
这个对谈和这些产品动作最适合给本文补上的,不是「腾讯做得更好」这种粗暴结论。它更像另一种问题意识:AI 下半场要争的,是谁能更诚实地识别真实问题、更稳地组织 Context、更早把反馈放进模型和产品闭环里。喊入口、改年号、急着证明自己没落伍,都不是核心。
阿里和腾讯的差别,可能正好落在这里:阿里这篇材料让我们看见,当组织急着用 AI 证明自己时,产品会怎样被烧穿;腾讯这场公开对谈和产品线则提醒我们,AI 真要进入企业现场,必须把长跑、真实问题、Context、Co-Design、闭环成本放在入口叙事之前。前者是伤口,后者是宣言。伤口未必比宣言低级,宣言也未必能避免伤口,但两者放在一起,能让我们更清楚地看见:AI 产品最终比的是谁能在真实组织里少制造一点自欺。
AI 办公产品必须先选择站在哪一边
企业办公产品最难的一点,是购买者、管理者、使用者和承受者经常不是同一批人。AI 加进来以后,这个问题不会自动消失,反而会被放大:模型到底帮谁看见更多,帮谁减少成本,帮谁获得掌控感,必须先讲清楚。
先回答用户到底是谁
在初始定位的构思中,用户究竟是普通员工还是老板的问题,始终没有闭环。
——《置身钉内》,「定位第二」,第 17 页
企业软件里最难的一件事,是购买者、管理者、使用者和承受者经常不是同一批人。
老板买单,员工使用;商家付费,消费者评价;平台抽佣,骑手履约;管理层要效率,基层要边界;发信人要确认,收信人要空间。一个产品如果只说「用户价值」,但不说这个用户是哪一方,它就很容易把不同人的利益冲突藏起来。
客户和用户不能随便混用。比如美团官网里写的是「以客户为中心」,同时也写到为消费者提供品质服务、支持小商户发展、承担社会责任。这里的「客户」更像一个生态概念,不止指某个正在付 SaaS 费用的人。平台型产品面对的是多边关系:消费者、商家、骑手、平台、监管和社会信任都在同一个系统里。某一方愿意付钱,不代表产品可以只服务这一方的短期诉求。
这个边界可以用一个平台产品例子说明。
如果我是美团到店 SaaS 的负责人,商家说差评影响经营,希望提供「商家删除差评」功能,这个功能到底该不该做?
先不要急着回答做或不做。可以先问三件事:商家的痛点是否真实;这个功能会不会改写消费者看到的公共事实;短期帮商家减压以后,平台长期信任由谁承担。
我的回答是:不做商家自助删除。
原因不是商家的痛点不真实。差评可能确实有恶意、误会、敲诈、同行攻击,也可能影响转化和店铺经营。SaaS 产品当然应该服务商家经营,不能把商家扔在舆论风险里。但让商家直接删除差评,会破坏评价系统最核心的信任资产。消费者会怀疑评价是否可信,其他商家会被迫加入同样的清理游戏,平台也会失去用评价连接供需双方的公信力。短期看,是帮一个商家减压;长期看,是把整个平台的信任抵押出去。
更合理的做法不是给商家删除权,而是给商家处理权。
商家可以发起申诉,提交证据,标记恶意评价、虚假交易、违规内容或已解决问题;平台要有审核、仲裁、申诉进度、处理理由和处罚机制。消费者应该能看到商家回复、平台处理状态和必要的争议标记。真实差评不能被抹掉,但问题解决、补偿完成、评价失实、违规攻击这些情况可以被清楚处理。
这个设计的立场是:SaaS 服务商家,但不能牺牲消费者判断权;平台保护交易效率,但不能牺牲信任资产;商家可以反驳和申诉,但不能直接改写公共事实。
这和钉钉 ONE 的问题是同一类。它同时服务老板和员工,服务组织确定性和个人边界,服务 AI 战略和真实工作。只说「用户」是不够的。老板是客户,员工是使用者,也是被系统持续影响的人;组织是购买方,个体是承受方;平台想要活跃,用户想要安静。产品如果不把这些角色拆开,就会把冲突藏进一句好听的「用户价值」里。
这一层冲突到碧桂园那个例子里变得更直接。基层保安、保洁这类工作链路明确的人,可能反而更适合被卡片式任务安排帮助。但原文写到,这个现场并没有被当成真正值得展开的方向:
当时有一个产品同事去广东拜访碧桂园。对方领导层非常重视 ONE 的能力,希望用卡片的形式,动态、智能地安排保安和保洁每天的工作内容和顺序。
不过无招并不欣赏这个共创 case。他的判断是,ONE 不是要服务保安保洁,而是要服务老板、管理者和高净值人群。
——《置身钉内》,「用户第四」,第 64 页
这就把问题摊开了:在企业软件里,「客户」常常就是大老板、高管、信息化负责人、采购决策者。他们有预算,有排期权,有组织动员能力,也有把系统强制推给员工使用的权力。普通员工当然也是用户,而且是数量最多、使用最频繁、最承受默认值后果的人;但他们未必有采购权、否决权和反馈权。
产品经理说「以用户为中心」时,还得继续追问谁有权定义用户。不问这一层,话语权很快滑向权力更大的一方:老板的痛点被写成业务价值,员工的痛感被写成适应成本;管理层的可见性被写成效率,基层的安静权被写成不配合;采购方的满意被写成成功,普通使用者的抵触被解释成教育还不够。
ONE 的特殊之处在于,这个冲突几乎写在产品基因里:它想做员工的工作秘书,又继承了钉钉站在发信人一侧的强触达传统。秘书应该替用户挡噪音、排节奏、留余地;发信人系统则天然想确认、催促、追踪和闭环。一个产品如果不先选边,就会变成两头都不像:对外说帮员工减负,实际不断替组织把责任更早推到员工脸上。
「老板和员工都是用户」这句话太圆滑,圆滑到没有判断。这里应该说得更硬一点:老板是高权重客户,员工是高频承受者;老板的焦虑可以直接变需求,员工的不适常常只能变成数据噪声、社交平台吐槽和绕开系统的小动作。AI 产品如果不承认这层权力差异,就会把「智能」做成权力意志的润滑剂。
现实当然不会那么理想。人在组织里,很多时候不是你想站哪边就能完全站哪边。付费方要看见,老板要闭环,客户要验收,项目要过会,团队要活下去。产品不可能每次都用价值观把需求挡回去。
但被迫低头,不等于只能把刀磨快。
更现实的平衡,是在满足付费方主诉的同时,尽量给普通使用者保留最小尊严和最低成本。管理者要看进度,可以给聚合态势,不默认暴露每个人的细碎状态。老板要催办,可以给分级触达,不默认把所有提醒都打到个人脸上。客户要差评治理,可以给申诉和仲裁,不给自助删除。组织要 AI 使用率,可以看具体任务节省了多少时间,不把 token、活跃天数和打开次数变成绩效暗示。
这种设计是在保护系统长期可用。普通使用者也在平台之内,而且每天让系统运转。今天产品为了一个高权重客户牺牲他们的判断权,明天他们就会用沉默、绕开、截图留证、线下沟通、抵触配置来把成本还回来。
站在普通使用者这一边,也有很现实的自保意味。大多数开发者、产品经理、设计师,在另一个系统里也都是普通使用者。今天我们给别人留一个关闭按钮、申诉入口、批量处理、解释理由、可撤回动作,明天我们自己也会在别人的系统里靠这些东西少受一点苦。与人方便,很多时候就是与己方便。
以后做 AI 产品或 Agent 功能时,第一步先别画入口,也先别急着拆工具。先写清楚:谁付钱,谁使用,谁被影响,谁承担错误,谁拥有关闭权,谁的信任资产会被消耗。如果这些人不是同一批,产品就必须明确本轮优先保护谁,以及为了保护他,愿意拒绝谁的短期诉求。
AI 要把掌控感还给人
谁先被提醒,谁被默认已读,谁需要解释,谁拥有关闭权,谁承担模型误判后的代价,谁能把自己的规则交给系统,谁只能接受系统安排——这些问题看似细小,却决定了一个 AI 产品究竟是在帮人掌握工作,还是帮工作更早地掌握人。
——《置身钉内》,「设计第三」,第 24 页
很多企业软件天然站在组织视角,关心可见、触达、闭环、效率、成本。AI 加进来以后,这些目标会更强。模型可以总结更多信息,系统可以推送更多提醒,Agent 可以执行更多动作,管理者可以看到更多过程。
公开产品资料里已经能看到这种方向。Microsoft 365 Copilot Dashboard 会按组织、团队和功能统计 Copilot 的许可、活跃用户、使用趋势和影响;Copilot adoption report 也帮助管理者看哪些组使用得更多、哪些功能使用更频繁。这类报表不天然是坏事。企业花钱买 AI 工具,当然需要知道有没有被用起来,哪里需要培训,哪些许可证浪费了。
类似压力在其他公司会以更直接的方式出现。Business Insider 在 2025 年 11 月报道,Meta 计划从 2026 年开始把 AI-driven impact 作为员工绩效里的核心期待,评估员工如何用 AI 交付结果、构建能提高团队生产力的工具。文中同时写到,Meta 不会把 2025 年个人 AI 使用率和采纳指标直接放进年度绩效,但会鼓励员工在自评里写出 AI 带来的成果。
Google 的例子更偏组织动员,目前还不能当作已经确认的单项绩效指标。上述报道提到,在大厂转向 AI-native 文化的背景下,Google 高层要求员工更主动地使用 AI,以便在 AI 竞争里保持领先。更值得看的是工具性质的变化:当 AI 从「你可以用」变成「组织期待你用」,员工对工具的心理账本就会改变。它原本是提高效率的选项,后来又多了一层证明材料的意味。
Amazon 的报道更能说明指标异化。Tom’s Hardware 转述 Financial Times 的报道称,Amazon 曾设定每周使用 AI 工具的内部目标,并用内部榜单跟踪消耗;文中还说,Amazon 表示使用数据不会进入绩效评价,但多名员工认为管理者仍在关注这些数据,于是出现了为了提高 token 消耗而使用内部 agent 平台的 tokenmaxxing。这个例子不用被读成「AI 都是假的」。它暴露的问题更具体:组织奖励使用痕迹时,使用痕迹就会被制造出来。
这些案例的证据权重不一样。Microsoft 的部分是公开产品能力,Meta、Google、Amazon 的部分主要来自媒体基于内部材料或员工采访的报道,不能写成「所有大厂已经这样考核员工」。但它们共同指向同一个风险:企业 AI 一旦进入组织管理系统,最先浮到管理界面的往往是使用痕迹,价值反而需要后续证明。产品仪表盘、内部 OKR、管理者汇报和员工绩效会把同一个问题反复推回团队面前:我们到底是在衡量 AI 有没有减少真实成本,还是在衡量人有没有留下 AI 使用记录?
下一步风险更大:使用率很容易从产品运营指标变成绩效暗示。一个组织如果只奖励「用了 AI」而不检查「AI 有没有降低真实成本」,员工就会学会制造 AI 痕迹。打开工具、刷 token、让 AI 参与不必要的流程,都可能变成新的在场证明。到那时,AI 没有减少表演,反而制造了一种更现代的表演。
企业 AI 的异化往往从这里开始:它本来可以是拐杖,帮人少走一点重复路;也可以变成尺子,替组织更精细地丈量人。拐杖的目标是让人走得轻松一点,尺子的目标是让管理者量得更准一点。两者都可以披着「效率」的外衣,但它们对人的意义完全不同。
一旦 AI 变成尺子,组织里会发生两次权力转移。第一次是工作定义权的转移:系统开始规定什么叫及时、什么叫积极、什么叫合格,人的节奏和判断被切成一张张卡片、一次次点击、一个个流程节点。第二次是价值判断权的转移:你做得好不好,不再主要来自同事、用户和真实结果,而来自仪表盘、评分、趋势线和模型摘要。
更麻烦的是,算法很容易给管理者提供一种「客观性外衣」。过去一个主管说你不够积极,至少还可以追问依据、解释背景、讨论例外;如果系统说你响应慢、AI 使用不足、任务风险高,管理者就更容易把判断包装成中立事实。技术这时会多出一层免责盾牌的作用:管理者可以把主观苛刻说成系统计算。
但如果 AI 只是让组织更早掌握人,它不会让人喜欢。它最多让人服从。
AI 的价值,应该包括把过去只有少数人享受得起的个性化服务下放给普通用户。老板和高权重用户天然有人替他筛信息、解释上下文、安排优先级、响应反馈。普通用户面对的是同一套默认规则和同一片信息洪水。
AI 如果只把老板级体验继续送给老板,价值并不大。它更应该帮助普通人获得一点过去只有人工秘书、助理、团队支持才能提供的东西:记住偏好,理解角色,少打扰,能解释,能撤回,知道什么时候不要替我决定。
「AI 秘书」这个词一定要拆开看:它到底是谁的秘书?
如果它站在员工这边,它应该帮员工过滤噪音、保留缓冲、合并重复、解释上下文、提醒风险,必要时替用户挡住不该立刻进入注意力的东西。如果它站在发信人和管理者这边,它就会变成另一种东西:它知道你没回消息,也能把消息顶到你面前,让你更难假装没看见;它能总结进展,也能让管理者更早拿到可追踪的证据。
这时它表面上还是秘书,实际上已经接近监工。更糟糕的是,它可能同时拥有两套话术:对员工说「我帮你减负」,对组织说「我帮你掌控」。这样的 AI 不会减少权力不对称,只会让权力不对称更聪明、更温和、更难反驳。
从这个角度看,AI 办公产品越到深处,越需要像一个懂边界的同事。
它应该知道自己什么时候只提供依据,什么时候可以代办,什么时候必须停下来问人。它应该把不确定性摊开,不把它包装成确定答案。它应该让用户训练它,不让用户被迫适应它。它应该让工作少一点混乱,别把人更早推入被催促状态。
管理确定性要少压给人
钉钉早年的胜利,给无招留下了一套很深的身体记忆:站在发信人一侧,替组织争取确定性,用强触达把事情往前推。
——《置身钉内》,「外部环境:2025 年的风向」,第 4 页
钉钉早期很多成功功能都在回答一个管理者问题:我说的话,对方到底看见没有;我交代的事,到底有没有往前走。
这个问题很真实。企业协作里,管理者购买软件,常常就是为了消解这种不确定性。已读未读、DING、审批、考勤、任务流转,都在把组织里的过程变得可见、可追踪、可催促。
这些功能有它们的价值。没有可见性,组织会靠更原始的人肉催促运转;没有确定性,任务会在口头承诺和模糊边界里掉下去。钉钉能从微信旁边长出来,靠的就是它没有回避管理者的焦虑。
但同一套成功经验进入 AI 工作入口时,会产生新问题。
AI 的主动排序、主动提醒、主动总结、主动已读,会进一步提高管理确定性,也会把不确定性从系统和组织那里转移到某个具体用户身上。系统不知道这条消息是否真的需要现在处理,就把它推出来;模型不知道这个摘要是否足够准确,就让用户承担判断;产品不知道哪些内容该默认出现,就先让所有人看见。
管理想要确定性可以理解,问题是确定性从哪里来。
一种做法是向下转嫁:让员工更早被看见、更早被提醒、更少有缓冲、更难说不知道。另一种做法是提高系统能力:让上下文更准确、权限更清楚、反馈闭环更完整、个性化更可靠、风险动作更可撤回。
前者快,后者慢。前者容易形成可见效果,后者需要长期建设。很多企业 AI 产品的分岔就在这里。
一个健康的 AI 工作系统,不能只替管理者获得确定性,也要替使用者保留掌控感。它应该让工作更清楚,而不是让人更透明;应该让责任更可处理,而不是让责任更早落下;应该让组织少一点混乱,而不是让个体多一点压力。
我读这篇文章时最强的感受也在这里:AI 办公产品当然要问「它能不能帮组织推进事情」,还要追问「它有没有让具体的人更好地处理事情」。
AI 还应该保护不注意的权利
智能是平权的,但是 context 是不平权的。
——《置身钉内》,「发心第一」,第 5 页
从这个角度看,钉钉和 AI Native 的冲突还可以说得更深一点。
钉钉过去很多成功功能,底层假设都是「事情需要人去做,工具负责推动人」。消息要已读,任务要催办,考勤要打卡,流程要流转,管理者要看见状态。这些功能有现实价值,企业协作本来就需要协调、提醒和责任分配。麻烦在于,这套设计天然把「人是否在场」当成系统可靠性的前提,把「谁能推动谁」当成协作效率的来源。
AI 时代更底层的变化,是一部分原来必须消耗人类注意力的事情,开始可以被工具、模型和 Agent 接过去。过去的问题是「哪个人现在应该被提醒去做」;现在更好的问题是这件事是否还需要人现在注意。如果需要,是谁、在什么时间、拿着什么证据、承担什么责任;如果不需要,系统就应该安静地处理、延后、汇总或等待更合适的时机。
已读、催办、优先级排序这类功能最容易出问题,也正是因为它们看起来像中性的效率功能,实际却在分配注意力权力。发信人和收信人并不对等。组织层级存在时,上级可以因为下级已读未回而追责,下级却很难因为上级不看、不回、不理解上下文而追责上级。所谓「发信人视角」和「收信人视角」在界面上可以对称,在生产关系里并不对称。
只优化注意力先后顺序是不够的。没有离场权的优先级系统,最后很容易变成更精细的催促系统。没有安静权的主动服务,最后很容易变成更聪明的打扰。没有拒绝权和解释权的 AI 排序,最后也会把组织偏好包装成算法判断,让被打扰的人承担更多解释成本。
Agent 时代更应该补上另一半设计:什么时候人可以不注意。
低风险、重复性、可撤回的事情,Agent 应该尽量替人接住。中风险的事情,Agent 可以先整理成批量摘要、候选方案和影响范围,让人选时间处理。高风险的事情,才应该把人拉回现场,而且要带着足够证据、明确选项和可审计后果。好的 AI 办公产品,应该让人可以放心离开屏幕一会儿,而不是更早被叫回屏幕前。
这和协作、管理并不冲突。恰恰相反,一个系统如果能让人安全地不在场,说明它真的理解了工作的状态、边界和责任。它知道哪些事可以等待,哪些事可以代办,哪些事必须升级;它知道什么时候应该保护接收方的注意力,而不是默认满足发起方的触达欲。
AI 产品如果只把旧协作软件里的已读、催办、打卡、审批重新包装成 Agent,就会把旧管理方式升级成更强的管理机器。AI 产品如果能重新设计注意力契约,让人知道什么时候必须在场,也知道什么时候可以离场,它才开始接近新范式。
工作不是消息流:先拆动作、状态和边界
工作不是一条消息流,也不是一组卡片。真实工作由动作、状态、责任、边界和上下文组成。产品形态要从这些动作里长出来,而不是先决定做 App、PC、卡片流或主动推送,再让用户把工作塞进去。
工作需要状态、责任和边界
工作并不会因为被做成卡片,就变成可以轻松消费的内容。
——《置身钉内》,「设计第三」,第 26 页
ONE 最吸引人的设想,是把钉钉里散落在群聊、日程、待办、会议、文档里的工作信息重新组织起来,让「人找事」变成「事找人」。这个方向本身并不荒唐。办公软件里最让人疲惫的部分,恰恰是人要不断在多个场域之间切换,靠自己的记忆和注意力把工作拼起来。
麻烦在这里:工作天然带着责任,不能直接按内容消费的逻辑处理。
信息流的前提是用户来消费内容。刷视频、看文章、看商品,用户面对的是一段段内容;内容可以排序,可以推荐,可以插入,可以被下滑跳过。工作不一样。工作里的每一条消息、每一个待办、每一次会议提醒,都可能连着责任、时机、上下文和人际关系。
看到一条消息,可能意味着对方知道你看到了。看到一个待办,可能意味着责任已经交到你手里。看到一个会议总结,可能意味着你需要确认它能不能分发。看到一个 AI 摘要,可能意味着你要判断它有没有漏掉关键条件。
换句话说,工作产品里的看见带有责任后果。它在重新安排责任什么时候发生、由谁承担、用户有没有准备好承担。
文章里反复提到的消息卡片和已读问题,正是这个矛盾最具体的例子。站在产品效率视角,把重要消息提前做成卡片,让用户少进一次会话,似乎是好事。站在收信人视角,这件事会变成「我还没准备好处理,它已经替我签收了」。站在发信人视角,收益又并不明显,因为他只看到一个已读,并不知道对方是在原会话里读的,还是被 ONE 的卡片推到了眼前。
这里出现了典型的收益和成本错配:产品维护了一个抽象正确的立场,但收益方没有明显体感,付代价的人却很清楚。
开发者做 AI 工具时也会遇到同类问题。比如一个 Agent 自动总结会议、自动识别任务、自动提醒未回复消息、自动标记风险、自动写入某个系统,表面上是在提高效率,实际上都可能改变责任发生的时间。
一个功能是否有价值,不能只看它有没有把信息提前拿出来。还要看用户因此多背了什么:
- 他是否更早暴露了状态。
- 他是否失去了延后处理的余地。
- 他是否需要解释模型误判。
- 他是否能关闭或撤回。
- 他是否知道系统为什么这么判断。
- 他能不能把自己的规则交给系统,而非只能接受系统安排。
如果这些问题没有回答,所谓主动服务很容易变成主动打扰。更糟糕时,它会变成系统替组织更早掌握用户。
这里还要区分两件很容易被混在一起的事:信息效率不等于企业效能。
企业里的效率至少有五层:
- 信息到达效率:谁知道了这件事,消息有没有送到。
- 信息理解效率:谁理解了背景、约束、优先级和风险。
- 决策效率:谁有权决定,谁愿意负责,分歧如何被处理。
- 执行效率:系统、权限、工具和人能不能真的把事情办完。
- 学习效率:做完以后,组织有没有沉淀判断,而非只沉淀记录。
钉钉早期的强项主要在第一层:让消息到达,让人看见,让流程流转。ONE 想往第二层走:让重要事情浮上来,让上下文更容易被看见。但很多企业的实际瓶颈,往往卡在第三层和第四层:权责不清,目标冲突,部门墙,权限不足,系统割裂,没人愿意拍板。
如果 AI 只是更聪明地提醒、更准确地摘要、更积极地催办,催促可能增长十倍,效率却没有跟上。一个组织的任务链路没有被重新定义,责任和权限没有被重新安排,Agent 再勤奋也只能在消息堆里跑来跑去,替旧流程加速内耗。
有效的企业 Agent,要从「消息对象」进入「任务对象」。一个任务不能只剩标题和待办,它至少应该有目标、背景、输入、依赖、权限、负责人、截止条件、验收标准、证据和回滚方式。没有这些,Agent 只能帮人找事,不能真的把事办完。
去掉形式主义,留下思考
无招在 2026 年 4 月的中国企业家商界木兰年会上还有过一个争议很大的说法:钉钉内部一千四五百人,严禁写文档;开会不准做笔记,会议纪要和后续跟进都交给 AI;讨论问题只准用白板,讨论完拍照,AI 自动分析照片和过程语音,再生成会议纪要和待办。他还说,如果公司里还有人天天写文档、以写文档自居,这家公司一定是过去式。
后来这个说法有了更完整的解释。中国企业家杂志整理的对话里,无招强调,去文档的本质是人不再亲手写文档,由 AI 按人的要求沉淀文档;员工把更多精力投入实际工作,减少层层管理模式,公司慢慢会发生变化。
围绕这次争议,网易这篇评论的反对意见很直接:写文档的能力,就是知识工作者的思考能力;目标、推演、总结、规划这类认知文档,必须由人亲自思考后写出来;一刀切禁止写文档,背后是不再信任员工的思考能力。这组反对意见的方向是对的,但还可以再往前分一层:要保住的核心,是判断权、作者身份和责任署名不能被 AI 接走。
如果只看字面,这件事很容易变成一个荒诞新闻:老板不准员工写文档,谁写谁挨批。但如果放进他这几年讲的「去文档、去软件、去中层」里看,它其实有一套相当连贯的内心逻辑。
这套逻辑大概是这样:
- 文档只是知识在旧办公系统里的静态容器之一。
- 很多文档主要服务汇报、流转、归档和给上级看,思考含量很低。
- AI 可以记录白板、语音、会议和操作过程,把原始信息自动整理成纪要、待办和后续行动。
- 人不应该再把时间花在排版、抄录、转述和层层汇总上,而应该回到高带宽的讨论、判断、创意和决策。
- 既然 AI 能直接把一线现场整理给决策层,中层作为信息搬运和过程追踪的价值也会被压缩。
这套逻辑有成立的部分。很多公司确实有大量低价值文档:周报、月报、会议纪要、项目状态、复盘模板、汇报材料、为了证明自己在做事而写的材料。它们消耗人的时间,却不一定让问题更清楚。AI 自动转写会议、整理纪要、抽待办、生成草稿、把白板变成结构化材料,当然有价值。很多时候,人确实不该再把生命花在把一场会重新抄成一份漂亮文档上。
白板当然有价值。好的白板讨论,是一种高带宽协作。人站在同一个空间里,把图、箭头、关系、冲突、边界条件摊开,比各自回去写长文档再异步评论更快。对早期创意、方案分歧、流程拆解、系统关系,白板经常比正式文档更接近思考现场。
这个判断合理的部分,是反对文档形式主义。如果一个组织把「写了文档」当成「想清楚了」,把「文档很长」当成「工作很重」,把「材料好看」当成「项目进展」,那确实该被打掉。AI 很适合拿来压缩这些低价值整理工作。
但不合理的一半,是把「写文档」整体当成旧时代动作。
文档也是一种思考工具。很多复杂问题,只有写下来,人才会发现自己没有想清楚。架构设计、产品边界、权限模型、事故复盘、法律责任、团队决策、长期规划,都无法靠白板涂完、AI 纪要生成就结束。它们需要定义概念、约束词义、记录取舍、保留版本、明确责任,也需要让不在场的人能够异步理解和反驳。
白板适合发散,文档适合收敛。会议适合交换信息,文档适合沉淀判断。AI 适合生成草稿和整理材料,但它不能替团队承担判断责任。一个组织如果只剩白板和 AI 纪要,很容易丢掉几样关键东西:谁对这句话负责,哪个版本才是决策依据,反对意见在哪里,边界条件有没有被保留,后来者能不能复盘当时为什么这样选。
更危险的是,去文档也可能变成另一种组织控制。过去,员工至少还能通过自己写的文档保留一部分解释权:我当时怎么理解问题,为什么这样判断,哪些风险我提醒过,哪些前提我没有同意。现在如果所有讨论都由 AI 中枢记录、整理、归档、分发,解释权就会从个人文档转移到系统摘要里。
表面上是减少文档,实际上可能是把组织信息的整理权、解释权和分发权集中到一个 AI 中枢。谁定义 AI 怎么总结,谁能看到原始记录,谁能修改纪要,谁能把待办派给别人,谁就掌握新的组织权力。
这和 ONE 的底层冲突是一脉相承的。
ONE 想做的是把消息、日程、待办、审批和文档重新组织成 AI 工作信息流;「去文档」想做的是把会议、白板、语音和过程资料交给 AI 自动沉淀。它们背后都有同一个信念:人不要再整理信息,AI 来整理;人不要再找事,事自己浮上来;组织不要再靠中层传递,系统直接把上下文铺到每个人面前。
这个信念很有未来感,也很危险。因为它太相信信息可以被自动整理成行动,太低估了人在写作、筛选、延迟、反驳和版本管理里的价值。工作带着责任流,文档也承载组织记忆。很多时候,工作就发生在写文档的过程中:把含混的直觉变成句子,把口头共识变成可检查的承诺,把一时兴奋变成长期可以回看的判断。
更稳的做法是把文档分层。人必须亲自承担文档里的判断,但不一定必须亲手完成每一个字。
- 低价值记录:会议录音、基础纪要、待办抽取、信息归档、格式整理,可以交给 AI。
- 状态同步文档:周报、项目进度、会议跟进、风险清单,可以让 AI 先写,但人要确认事实、删掉误读、补上遗漏。
- 认知类文档:PRD、技术方案、产品复盘、战略推演、组织制度,需要人先给判断框架,AI 只能辅助表达和补充材料。
- 责任类文档:法务、人事、绩效、重大决策、权限变更、事故定责,必须有人署名、审阅、负责,不能让 AI 摘要直接变成组织事实。
AI 可以帮助写文档,但不能取消人的作者身份。白板可以帮助讨论,但不能替代决策记录。去文档可以打击形式主义,但不能顺手打掉组织的知识资产和个人的解释权。
AI 可以接走记录、整理和格式,但不能接走人的判断、署名和责任。去文档一旦变成去思考,效率革命就会滑向组织失智。放回《置身钉内》看,这件事反而像一个预告。无招讨厌的除了文档,也包括慢、静态、中间层、人工整理和旧办公软件的边界。他想把组织推到一个更实时、更高带宽、更 AI 中枢化的工作方式里。ONE 的「事找人」、悟空的「打碎钉钉」、去文档的「AI 自动沉淀」,都是同一套想象的不同切面。
这套想象当然可能有未来。危险在于:如果它由一个强控制欲的组织来实现,知识工作者得到的未必是解放,也可能是一个更实时、更透明、更难退出的系统。
先拆工作动作,再选产品形态
到 10 月中旬,团队已经围绕卡片、排序、已读折腾了一大圈,我逐渐强烈意识到一件事:或许设计不该先从卡片开始,而该先从用户动作开始。
——《置身钉内》,「设计第三」,第 46 页
这句话对 AI 产品尤其关键。AI 产品太容易先迷恋形态。聊天框、卡片流、悬浮球、智能工作台、自动驾驶、Agent OS、多 Agent 运行态,这些词都很有吸引力,也很适合汇报。它们能让人觉得未来已经摆在屏幕上。
产品设计更应该从原场域动作开始。
IM 原场域里,用户不是只在读消息。他还在查找会话、扫 last message、按项目或角色分组、置顶重要群、把某条会话标未读、判断现在要不要点进去、决定是否晚点回复。很多动作没有被写成显性的功能卖点,却共同构成了用户的安全感。
卡片拿走了「读」这个动作,却很难完整承接查找、分组、延后、标记和管理。它适合把一件事端到眼前,不适合让用户在复杂工作网络里自己调度。于是系统以为自己减少了一次点击,用户感受到的可能是失去了一整套熟悉的掌控方式。
原文后面把这件事算成了更直观的时间账。
消息列表承载的查找会话、管理会话的职能在卡片形态上是完全丢失的,我们做了语音指令能力来填补搜索查找,另外在卡片上加入搜索图标来缓解前者,但是效率已经大大降低。
同时,在 IM 列表上找到这个高频会话只需要 2~3 秒,如果你把它设成置顶,你可以凭手感在 1 秒内找到它。但在卡片,15 秒是一个非常保守的估计。
——《置身钉内》,「设计第三」,第 44 页
这就是产品形态压过工作动作之后最具体的损失:为了展示一个新的 AI 信息流,用户原来靠肌肉记忆、置顶、last message 和空间位置完成的动作,被换成了重新识别卡片、判断下一张是谁、再用搜索或语音找回会话。表面上是减少点击,实际是在增加确认成本。
为什么团队还会坚持做卡片?因为卡片有叙事价值。它看起来像新入口,适合演示,能体现主动服务,也能把消息、待办、审批、日程这些旧钉钉对象包装成一个统一的 AI 形态。问题是,叙事成本由团队支付,迁移成本由用户支付。当一个形态主要用来证明「我们做了一个新东西」,它就很容易把用户原本顺手的动作重新发明一遍。
这件事放到日常开发里,就是一个很朴素的规则:不要先决定容器,再寻找内容。
顾家的例子就是这个问题在 To B 现场里的版本。
两位 BD 聊起顾家当时正在定制开发一个内部的轻量 Teambition,呈现在 PC 端的主页,解决各种工作信息分散在钉钉各场域的痛点。
这本该是一个绝佳的、能验证大模型进入真实业务语境的共创场景。但在沟通现场,当聊到我们当前主要在设计移动端时,对面的两位前线 BD 同学突然沉默了,并且彼此对视了一下,眼神中流露出了明显的犹疑。
——《置身钉内》,「To B or Not To B」,第 47 页
这不是一个小小的端侧选择。企业里的深工作大量发生在 PC 端:写文档、填表格、看长消息、跨系统查资料、做汇总、改流程、处理复杂审批。移动端适合提醒、轻量读取和快速确认,但不天然适合完整承载工作闭环。ONE 主力押在 App 端卡片流上,就容易把「提醒用户有事」误当成「帮用户把事做完」。顾家想要的是贴着自己业务长出来的 PC 工作台,ONE 给出的却更像一个移动端信息入口,这里已经不是用户有没有被教育的问题,而是产品形态和真实场域没有对齐。
做一个 AI 助手前,先问用户原来在做什么:
- 他是在读,还是写。
- 是在查找,还是确认。
- 是在执行,还是判断是否要执行。
- 是在快速扫过,还是深度处理。
- 是在推进工作,还是在保护自己的节奏。
- 是想让系统替他决定,还是想让系统给他更多依据。
容器只是结果。卡片、列表、聊天框、表格、面板都不是天然先进。一个旧列表可能痛苦,但它可能给了用户足够强的预判和可控性。一个新卡片看起来精致,却可能让用户不知道下一张是什么,也不知道看见以后会发生什么。
AI 产品的复杂性就在这里。模型能力越强,越容易让设计者相信「系统可以替用户多想一步」。但用户未必想被替代一步。他可能只是想少一点噪音,多一点依据,保留最终行动权。
不合理要求先看必要性
钉钉面试前要先完成的那份大作业,题目是「族谱上钉」。要求描述得比较模糊,大意是:把家族成员拉进钉钉,建立一个 6 人以上的族谱组织,让他们在上面真实活动,并基于体验给出产品见解。
坦白说,这件事我没有真正完成。
我家里人比较少,能真正使用钉钉的人更少,无法满足「6 人以上家族组织」的要求。不过我想,做这个作业核心是考察我的产品洞察,敏捷响应,和纳投名状。所以我做了代偿的证明工作:那个周末我去本地图书馆查阅真实的大型族谱,用表格和文档为别人的族谱做编撰和数字化;联系专门做族谱生意的商家,调研商业链条和可能的产品方向;也动员朋友上钉钉,搭了一个出境旅游前事项沟通的朋友组织。
这些工作不算少,我觉得也证明了我的工作能力,并纳上了投名状。
他反复追问:为什么做不成?
父亲家还有人吗?母亲家还有人吗?外公外婆还在吗?真的找不到了吗?真的凑不齐六个能上钉钉的家人吗?
——《置身钉内》,「发心第一」,第 6 页
我至今仍不完全认同他的判断,也认为这是一种对人的服从性高于对人的能力的考察。你可以说这是挑选理想主义伙伴,也可以说这是 PUA;可以说这是创业精神,也可以说这是权力关系下的过度索取。
——《置身钉内》,「发心第一」,第 7 页
比如说,就有同事建议我晚上 6 点钟直接回家休息,9 点半再来,开完晚会再回家。
——《置身钉内》,「望舒(书)行动」,第 79 页
2026 年 4 月 2 日晚上,SM 突然通知所有 SM 和 PD 12 点前不许下班,看飞书那栋楼几点熄灯。
看街对面的竞对几点熄灯,仿佛看见对方的灯还亮着,就能反推出对方的意志还在燃烧;再推演到只要我们的灯也不灭,就能抵消战略上的不确定。
——《置身钉内》,「望舒(书)行动」,第 79 页
这些事情不能只用「离谱」两个字处理。更有用的拆法是先问两层问题:
- 这件事有没有必要。
- 如果有必要,是否必须用这种方式做。
族谱上钉这件事,明面上当然可以解释出合理性。候选人要体验钉钉,要理解组织关系,要在真实场景里发现产品问题,要证明自己有动员能力和产品洞察。这些都不是完全无意义。
关键在于,它为什么必须拉真实家人。产品体验可以找真实用户、朋友组织、商家组织、社群组织;组织关系也可以从别人的族谱、商业服务、家庭协作场景里研究。作者后来做的替代方案,如果明面目标是产品洞察和用户研究,其实是有效的。它甚至更像产品经理应该做的事:拆问题、找 proxy、做调研、补证据。
替代方案到底是为了什么,需要先分清两类目标:
- 明面目标:拿到产品洞察、验证组织场景、证明研究能力。
- 自我边界目标:认真完成任务,同时不把家人和私人关系交给组织消耗。
作者做的代偿工作,在这两类目标上都说得通;它没有满足的,是第三类隐藏目标:管理者想看候选人愿不愿意照字面完成要求。
如果管理者想看的核心是服从,替代方案就天然无效。当一个替代方案已经满足明面目标,却仍然不能被接受,通常说明真实目标不在明面上。族谱作业真正考的就会变成三个问题:你愿不愿意为了组织目标动用私人关系;你愿不愿意把工作软件带进家庭边界;你愿不愿意接受公司目标可以越过个人生活。
面对不合理要求,不能只问「有没有办法完成」。还要问:
- 它解决的真实问题是什么。
- 它要求我交出的代价是什么。
- 这个代价是否必须由我本人、我的家人、我的健康或我的私人关系承担。
- 有没有更低侵入、更可验证、更不伤害边界的替代方案。
- 如果替代方案被拒绝,拒绝的是方案能力,还是拒绝我没有表现出足够服从。
现实一点讲,人不总是有资格立刻硬刚。人在屋檐下,要交房租,要保工作,要过试用期,要面对权力不对等。所谓先接受现实,首先就是承认:组织不一定按理性目标行动,很多要求背后有隐藏指标,很多管理者要的是可见投入、随时响应和情绪安抚,结果反而退到后面。
但接受现实不等于内化现实。可以低伤害应付的形式要求,未必每次都要正面冲撞;能用替代证据完成的,就尽量把它转成证据;一次性、低风险、对他人无害的表演性动作,可以作为职业生存策略处理。可一旦要求开始动用私人关系、伤害健康、侵犯他人边界、制造虚假数据,或者把组织焦虑转成个人长期义务,就不能再把它美化成敬业。
「拉几个人糊弄过去」也许能通过某一次考验,但它证明的是你愿意为过关生产表演,不是产品能力。找替代方案则证明你还在按问题本身工作。前者是生存技巧,后者是专业判断。它们在现实里都可能出现,但不能混成同一种东西。
事先怎么判断对方到底要能力还是服从?可以看三个信号:对方是否只接受字面完成,不接受等价证据;对方追问的是结果质量,还是为什么没有照他说的做;替代方案越充分,对方越不讨论方案,只讨论态度。出现这些信号时,替代方案仍然有价值,但价值变了:它不再是为了说服对方,而是为了让自己看清真实规则,决定这场游戏还要不要继续玩。
巡视办公室、要求晚下班、劝人「先下班再回来」、看飞书几点熄灯,也是同一套逻辑。
它有没有意义?有,但意义不在产品。它的意义是给管理者制造可见投入:灯还亮着,人还坐着,群里还响应,项目还在燃烧。它能安抚焦虑,也能训练服从,却很难制造判断力。
如果换我,我不敢说自己每次都会比作者更硬。人在不同阶段,议价能力不一样。有时为了保住工作、避免直接冲突、让某个关键节点过去,确实会选择低成本配合一下。但我会把它归类成临时求生动作,不是正确管理方式,更不是值得推广的文化。
更稳的做法,是尽量把「人在不在」改成「交付物和判断是否清楚」:
- 需要进度,就给异步状态、风险列表和下一步承诺。
- 需要现场,就约明确时间,不用全天候等候。
- 需要信心,就给可验证结果,而不是给熬夜时长。
- 需要加班,就说明业务后果、截止时间和补偿安排。
- 需要长期投入,就保护深度工作和健康,而不是让每个人持续表演投入。
更根本的问题,是组织把什么当作价值。把在场当价值,大家就会学习如何被看见;把判断当价值,大家才会学习如何把事情做对。
这套思路也可以放回 AI 产品和 Agent 设计里。Agent 不能只帮用户执行不合理要求,也不能一上来就做道德裁判。它应该先拆:
- 明面目标是什么。
- 真实目标可能是什么。
- 有没有必要。
- 有没有低伤害替代方案。
- 成本和风险落在谁身上。
- 哪些边界不能越过。
好的 Agent 应该帮助人接受现实里的约束,但不帮助坏现实变得更顺手。它可以帮用户糊住短期漏洞、组织材料、降低冲突、争取缓冲;但当需求明显在侵犯私人边界、透支健康、制造虚假确定性或强化服从性测试时,它也应该提醒用户:眼前的难题已经越过产品范畴,进入边界问题。
AI Native 不是加速旧流程,而是重建判断和契约
这组内容落到我们自己的开发现场。企业 AI 要先解决信任、风险和契约问题;Agent 要能加速执行,也要能识别坏前提;Skill 和 AI Native 不是把旧流程包装成新名词,而是把业务对象、工具边界和停止条件重新写清楚。
LLM 稳定性要落到工程和契约
当模型幻觉可能出现在审批意见、周报总结、跨部门同步中时,「秘书」的可靠性不再是技术指标,而变成了组织信任问题。
——《置身钉内》,「发心第一」,第 10 页
这个问题在大组织里很容易被写得很高:人情、伦理、道德、法律、组织信任、产品责任,全都可以被拉进来。
这些层面都有现实依据。企业 AI 一旦进入审批、消息、会议、客户响应和管理链路,模型输出错误就会超出「回答不准」的范围。它可能影响业务动作,影响责任分配,影响用户是否信任系统。
但只有宏大叙事也不够。稳定性首先要有工程抓手。
规范化提示词、结构化输出、schema 校验、RAG 引用、多模型校验、eval 集、关键节点人工确认、dry-run、影响预览、fallback、审计日志,这些都是具体工作。没有这些,只谈伦理和组织责任,很容易变成漂亮但无用的解释。
反过来,只谈 prompt 技巧也不够。企业产品里的稳定性要看完整流程稳定,不能只看单轮输出:
企业级 AI 的核心是信任工程。消费级 AI 里,一次生成不够好,用户可以重试、改 prompt、换工具,失败成本通常还在个人可承受范围内。企业级 AI 进入的是审批、客户、权限、数据、组织责任和跨人协作。错误不会平均分布,少数高风险错误才最要命:错批、错发、错看、错漏、错触达、错归因。
这时不能只问「模型大多数时候准不准」,还要问它错的时候会伤到哪里。低风险场景可以允许模型做草稿,比如帮用户改写文案、总结会议、生成待办候选。中风险场景要把建议和执行分开,比如推荐回复、推荐日程、推荐审批意见。高风险场景必须有 dry-run、影响预览、人工确认、权限校验、回滚和审计。企业 AI 的成熟度,要看它能不能分清哪些动作可以自动化,哪些动作暂时必须留给人。
- 模型什么时候可以自动执行。
- 什么时候只能给建议。
- 什么时候必须让用户确认。
- 用户确认时能看到什么影响预览。
- 错了以后能不能撤回。
- 谁有权限执行。
- 谁能看到审计。
- 系统如何记录当时的上下文、工具调用和用户选择。
更实际的拆法,是把 LLM 稳定性分成三层:
- 工程控制:让模型更少乱说,更容易被校验,更容易回归测试。
- 产品边界:按风险决定自动化程度,低风险可以自动,中风险要确认,高风险要 dry-run 和二次确认,不可控就降级为只读建议。
- 组织契约:用户知道系统在做什么,知道错了怎么办,知道谁能追责,也知道自己不用替模型背锅。
这三层缺一层,稳定性都会变形。
只有工程控制,没有产品边界,系统会把看似格式正确的结果推向高风险动作。只有产品边界,没有工程控制,确认卡片里放的仍然可能是脏判断。只有组织契约,没有前两层,文档写得再漂亮,用户也不会真的信。
AI 会放大坏前提
如果一个团队每天都在动,却没有更接近正确问题,那不叫敏捷,叫奔波。
——《置身钉内》,「敏捷第五」,第 76 页
AI 加进开发以后,最危险的变化在于:坏前提也能被更快实现。代码写得更快,只是这件事的表层。
过去一个方向错了,团队要花比较久才能把它做成一个看起来完整的东西。需求要写,接口要约,页面要画,前后端要联调,中间会有很多摩擦。这些摩擦当然烦人,但它们也客观上给了团队一些重新思考的机会。有人会在评审时问一句:这个入口真的有人用吗?这个状态能不能关?这个权限谁来兜底?这个页面是不是只是为了汇报好看?
AI 把这些摩擦拆掉了很多。PRD 可以更快写,代码可以更快生成,UI 可以更快拼出来,接口 mock 可以更快补齐,竞品表格可以更快整理,测试用例也可以更快列出。于是一个前提即使是错的,也更容易在短时间内长出一整套配套物:页面、文案、接口、埋点、测试、汇报材料和演示视频。
原文在讲「只做表面优化」时放过一张图,很适合概括这类状态:问题本身没有被重判,解决方案却不断往同一处挤。

这类现状现在很常见:产出物变多了,判断没有同步变好;局部任务变快了,系统性问题没有变少;每个人都能更快地完成自己那一段,但没有人更容易回答「这件事到底该不该做」。
它会在几类场景里反复出现:
- 产品前提没校准。用户抗拒的本来是责任转移,团队却让 AI 快速生成三版更柔和的文案、两版更轻的动效、一个更显眼的关闭按钮。东西越来越完整,问题没有变。
- 业务边界没想清楚。一个 Agent 能把审批、日程、消息、文档都串起来,demo 很顺,但权限、审计、失败恢复、冲突处理和人工接管都还只是口头承诺。越快串起来,越容易掩盖边界还没成立。
- 组织目标没分清。老板想要 AI 感,用户想要少打扰,商业化想要入口,团队想要当天有进展。AI 可以很快生成一个同时看起来满足所有人的方案,但它只是把冲突包装进一个更精致的界面里。
为什么会这样?
- AI 降低实现成本,判断成本依然留在人这边。写代码、写文档、做 demo、改样式、补测试,都能被模型加速;但判断用户是不是真的需要,判断默认值会不会改变责任,判断一个流程失败后谁来承担,仍然要靠人理解现场。
- AI 擅长补全,默认不太会质疑前提。只要给它一个方向,它会自然帮你把这个方向写得更完整、更合理、更像已经成立。它很少自己停下来问:这个需求来源可靠吗?有没有可能用户根本不想迁移?有没有可能我们在替组织转嫁成本?
- 生成比验证便宜。一个 Agent 几分钟能生成一套方案,但验证这套方案是否真的改善用户的一天,可能需要访谈、灰度、日志、回访、错误样本和长周期观察。于是组织会天然偏向便宜的生成,绕开昂贵的验证。
- 局部正确很容易伪装成整体正确。一个按钮实现正确,一个接口返回正确,一个 prompt 输出正确,一个页面截图正确,都不代表产品判断正确。AI 越能把局部做得漂亮,整体方向的问题越容易被漂亮局部遮住。
- 旧组织指标没有同步更新。很多团队仍然用进度、产出、截图、需求关闭数、上线频率来评价项目。AI 让这些数字更好看,却不保证用户迁移成本下降、信任增加、返工减少、系统地基变厚。
AI 时代更需要一种反直觉的纪律:在加速执行之前,先减速判断。
具体做法可以很朴素:
- 写前提卡。每个明显会进入开发的 AI 需求,都先写清楚:这个需求来自谁,服务谁,解决什么真实动作,如果不做会怎样,做错了谁付代价,成功信号是什么,停止条件是什么。没有这些,先不要让 Agent 大规模铺代码。
- 让 AI 先反对自己。一开始先别让模型生成实现方案,先让它列出这个需求可能错在哪里,哪些用户不会买单,旧场域里有哪些动作会丢失,哪些风险被包装成了体验问题。AI 很会执行,那就先把它用在前提审查上。
- 分清探索和执行。探索阶段,AI 应该帮团队扩大视野、找反例、拆用户动作、列风险和设计验证;执行阶段,AI 才负责生成代码、补测试、改文案、做自动化。不能把「能快速执行」误当成「已经完成探索」。
- 给地基能力单独记账。权限、审计、日志、回滚、评测、反馈闭环、个性化、失败恢复,不要只在出了事故以后才补,也不要永远排在可截图功能后面。它们关系到 AI 产品能不能长期运行,属于产品地基。
- 设补丁停止线。如果一个方案连续三次都在补同一种痛感,就不要继续问「怎么补得更舒服」,而要回到「这个方案是不是一开始就错了」。比如用户怕已读,就不能只一直补预览、横滑、跳过和摘要,也要重新问:这个已读到底该不该发生。
- 把验收从「东西做出来」改成判断被验证。一个 AI 功能是否完成,不应该只看页面有没有、接口通不通、模型能不能答,而要看用户是否真的少了成本,风险是否被分层,失败是否能恢复,日志是否能解释,团队是否学到了一个更可靠的事实。
AI 最适合加速的是低价值重复和可验证执行,不适合替人跳过判断。工具越快,越要把前提检查、风险分层和真实验证做成流程。否则 AI 不会让组织更聪明,只会让组织更快地把旧问题做成新系统。
Agent 要有打断权
一个人提出一个念头,很快就会开始保护这个念头;一个团队做出一个形态,很快就会开始解释这个形态。
——《置身钉内》,「用户第四」,第 55 页
如果把这些判断沉淀到 Agent 或 Skill 里,最重要的一条是:Agent 不能只会顺着做事。会做事当然重要,但只会执行会把坏前提做得更厚。
现在很多 Agent 的默认姿态还是执行器。用户说做一个页面,它就做页面;用户说加一个入口,它就加入口;用户说把内部 API 包成 CLI,它就去包;用户说继续优化这个方案,它就继续补文案、补交互、补测试、补 demo。它也许会提醒一句风险,但只要用户没有明确叫停,它大概率还是往下做。
这在简单任务里没问题。改一个样式、查一个报错、补一个脚本,Agent 当然应该尽量顺手。但一旦进入产品设计、业务流程、权限写入、组织协作、用户默认值和高风险自动化,Agent 就不能只是听话。
它应该有几种明确的打断动作:
- 前提打断:用户要求继续做某个方案时,如果 Agent 已经看到真实问题可能在责任流向、权限边界、迁移成本或用户动机上,而不是样式、文案或入口上,它应该先停下来,把问题说清楚,别继续生成更多补丁。
- 风险打断:只要涉及写业务数据、改变用户可见状态、默认开启主动提醒、代替用户确认、暴露已读状态、批量操作或不可逆动作,Agent 应该默认进入风险分层。低风险可以继续,中风险要确认,高风险要 dry-run、影响预览和审计。
- 验证打断:如果一个需求只有想象中的收益,没有真实用户行为、没有反证信号、没有停止条件,Agent 应该要求先补验证计划。它可以帮忙设计实验,但不应该马上铺代码把假设做得更像真的。
- 沉没成本打断:当一个项目连续几轮都在解释自己、保护自己、补材料、补 demo,却没有更接近真实使用,Agent 应该提醒:现在可能该讨论停止条件了,继续实现未必是正路。
这件事不能只靠 Agent 的「性格」或某次对话里的临场发挥。它应该写进 Skill,写成稳定的工作流。什么时候直接执行,什么时候先问前提,什么时候必须要求 dry-run,什么时候拒绝继续扩大实现,什么时候把「停止项目」当成可选方案,都应该有规则。
有价值的 Agent,不能只停在「用户说什么就做什么」。当用户快要把错误前提做厚时,它要敢于轻轻踩住刹车。这种不服从感的目的很简单:保护用户的时间、组织的资源和产品的判断力。
Skill 要少而准
很多时候根本不是 skills 的问题。参见 Claude Code,反而在缩减自己 skills 的规模。
——《置身钉内》,「错误的注意力导致错花的时间」,第 77 页
「错误的注意力导致错花的时间」这一节里,作者关心的不是 skill 有没有用。她关心的是组织把注意力投错了。
她先把钉钉和 Claude Code 放在一起对比:钉钉投入的人力、工时和组织配合度,可能远远高于 Claude Code,但实际执行效果很差,因为时间被用在了不对的地方。skills 就是她举出来的例子:老板想做 skills,于是很多人被分配去做 OPT 和一人公司 skill,但她的判断是上面这句。
后面她还补了一层更具体的原因:AI 是服务人的,客户只会比内部员工更不会写 skill;算力消耗高,不一定是单个 skill 没优化好,也可能是 cache 计费、context 管理、定时任务窗口累计和底层 infra 的问题;产品经理的时间有限,应该在客户服务、交互设计走查、成本优化之间判断优先级,不要被迫把大量精力压到 skill 单例成本优化上。
这段上下文很重要。作者不反对 skill 本身,她反对的是把 skill 当成组织运动、成本替罪羊和可见产出。
组织一旦把「做 skill」定义成正确方向,就会不断要求人去补 skill、写 skill、优化 skill、汇报 skill。skill 数量会变成一种可见产出,像页面数量、需求数量、迭代数量一样,容易被拿来证明团队在做事。但 skill 数量不能直接等同产品价值。它只是让 Agent 更稳定完成某类任务的一层方法封装。
这个理解和官方产品定义也能对上。OpenAI Help Center 对 ChatGPT Skills 的说明把 Skills 解释成可复用、可分享的工作流,可以包含指令、示例和代码,用来让 ChatGPT 更一致地完成特定任务;Skills 会在有用时被自动使用,也支持 ChatGPT、Codex 和 API,但目前不会在产品间自动同步。
Claude Code 的文档也把 skill 放在类似位置:Claude Code skills 用来封装重复工作流,适合当你总在聊天里粘同一套说明、清单或多步流程时创建;它还强调 skill body 只有在使用时才加载,长参考资料在需要前几乎没有成本,但一旦加载会留在上下文里,所以 body 要保持简洁。
这说明 skill 更像工作流和注意力管理机制,不是业务系统本身,也不是把所有场景都做成小剧本。Codex / Claude Code / GPTs 的差别可以再细分,但在这章里它们只是旁证:成熟的 Agent 产品不会把「skill 越多」直接等同于「能力越强」。
这里分三层看会更清楚:
- GPT 是一个面向用户的定制助理容器,负责身份、语气、知识、能力和外部动作。
- Codex 是面向开发现场的 Agent,负责理解仓库、编辑文件、执行命令、验证结果。
- Skill 是其中一层可复用的工作流说明,负责把某类任务做稳。
把三者混在一起,就容易把业务系统、工具契约、知识库、方法论和工作流全塞进 skill,最后得到一个更难维护的提示词目录,离 AI Native 反而更远。
我理解的 skill,应该是这样的:
- 服务高频、稳定、可复用的工作流。不要每个临时想法都建一个。
- 写清什么时候用、什么时候不用。不只写「如何做」。
- 帮助 Agent 判断前提、风险和停止条件。不只帮助 Agent 更快执行。
- 把稳定业务能力交给结构化 API / Tool contract。skill 保持在方法论、流程、校验和编排层。
- 包含反例、打断条件、验证命令和失败兜底。不能只有顺利路径。
- 小而硬。减少上下文噪音和决策摩擦,别做成新的知识垃圾场。
这里分两个判断:
- 要不要尽可能多做 skill。
- 一个 AI 产品要不要把大量精力用在 skill 上。
这两件事相关,但要分开判断。
先看「要不要尽可能多做 skill」:不要把 skill 做成数量竞赛。这个判断我比较明确。
skill 的价值不在多,在少走弯路。一个高质量 skill 能把稳定场景、触发条件、禁用条件、验证动作和失败兜底写清楚,让 Agent 在该稳的地方稳下来。反过来,几十个相似 skill、几百个来源混杂的 skill,不会自动变成几十倍能力,反而会制造路由噪音、上下文成本、维护成本和安全入口。
从这个角度看,钉钉大规模做 skill,和开源社区里有人搜罗几百上千个 skill 全量安装,其实是同一类冲动:都默认「能力可以通过堆 skill 变多」。钉钉是组织版,开源全家桶是个人版。两者的共同问题,是把 skill 从一种工作流封装,想象成能力本身。
钉钉不是错在「做 skill」。企业办公平台当然可以有一批稳定的业务 skill,比如报销、排班、客户跟进、会议纪要、合同审查、知识库问答。问题在于,skill 太容易被当成产品故事和组织产出:可以分配人去做,可以汇报数量,可以给客户演示,也可以包装成「超级个体」和「一人公司」的能力目录。
Claude Code 面对的是开发者工具。Claude Code 官方文档把它定义成能读代码库、改文件、跑命令并接入开发工具的 coding agent。开发者真正需要的是稳定的代码理解、文件编辑、shell、版本控制、测试、上下文管理和工具调用。这里 skill 太多反而可能变成负担:占上下文、增加路由不确定性、让模型在相似流程之间犹豫,也让用户不知道到底该调用哪一个。
Claude Code 的方向更接近「少加载、按需加载」。它不是不要 workflow,而是把 workflow 当成上下文成本来管理:常驻的东西要少,触发条件要准,复杂步骤按需加载。这个方向和「缩减 skill 规模」并不矛盾,因为开发者工具的核心价值不在 skill 目录多漂亮,而在它能不能稳定理解代码、执行工具、验证结果、减少判断成本。
类似地,ECC 这类开源项目作为样板库、对照表、灵感来源和迁移工具有价值;它能让人看到一个工作流可以怎样拆成 skill、rules、hooks、MCP 配置和脚本。但如果把它当成默认常驻能力全量安装,问题就来了:几百上千个 skill 带来的不是几百上千种能力,而是几百上千个触发描述、路由候选、维护版本、供应链入口和概念噪音。
在「是否要尽可能多做 skill」这个问题上,我的结论很明确:不应该。一个成熟 Agent 系统要追求少量高质量 skill,不要追求一个看起来很壮观的 skill 目录。外部 skill 仓库更适合作为候选材料和灵感市场,不适合作为默认全家桶;团队公共 skill 更应该经过 review、版本锁定和安全检查。
再看「产品团队要不要把大量精力用在 skill 上」。这里答案更微妙:可以投入,但不能把 skill 当主战场,更不能把 skill 当所有问题的默认解法。
如果一个业务场景稳定、重复、可验证,而且用户确实需要 Agent 反复完成同类任务,那产品当然应该沉淀 skill。比如企业办公里的报销、排班、合同审查、会议纪要,开发工具里的发布检查、PR review、故障复盘、文档生成,都可能值得做成 skill。这里投入精力是合理的,因为 skill 在降低真实使用成本。
但如果产品的问题其实在定位、用户、交互、权限、成本结构、上下文管理、底层工具契约或组织优先级上,把大量人力压到 skill 上就会变成错花时间。原文里作者说的恰恰是这个:成本高不一定是 skill 没优化好,也可能是 cache、context、定时任务和底层 infra 的问题;客户不会用,不一定是 skill 不够多,也可能是产品没有把真实任务拆清楚。
无招要求团队做 skill 这件事,本身不能简单判死刑。作为一个 AI 办公入口的探索,它可以理解;企业办公确实存在大量可沉淀的稳定流程。但如果它变成「老板想看 skill,大家就去做 skill」「成本有问题,PM 就去优化单个 skill」「产品没想清楚,团队就先堆一批 skill 证明在做 AI」,问题就很清楚了:skill 被用来证明组织在做 AI,却没有把产品推近真实任务。
一句话说:skill 可以是工具箱里的好工具,但不应该变成产品的遮羞布。成熟的 Agent 产品,应该把业务能力做成稳定工具,把复杂判断写进规则,把重复流程沉淀为少量高质量 skill,再让 Agent 在必要时调用。skill 的价值不看数量,也不看汇报时有多好看,而看它能不能让产品更接近真实任务。
AI Native 要重建业务对象
旧时代的强管理手感,和 AI 时代需要的个性化、成本感、边界感、失败兜底之间,还没有完全接上。
——《置身钉内》,「总结:看得远,打得急」,第 93 页
ONE 的问题远不止某个卡片、某个入口或某个模型能力没做好,它更像是在强行融合新旧时代。
旧时代的钉钉有自己的成功经验:消息、日程、待办、审批、已读未读、强触达、管理确定性。AI 时代来了以后,如果只是把这些东西重新包装成卡片流、主动服务、Agent 入口,底层的产品抽象其实没有变。只是旧系统换了一层更像未来的外壳。
很多所谓 AI Native 产品也会犯同样的错。
给旧产品套一个聊天框,只是多了一个对话入口。把旧页面重排成卡片流,只是换了展示容器。把消息、日程、审批、待办重新包成一个 Agent 入口,也只是把旧流程搬到新壳里。甚至把内部系统的 API 包成 CLI,再给 CLI 套一组定制提示词,让员工通过 ChatUI 跑一堆临时流程,也只能算旧系统换了入口。
这类做法看起来追上了时代,实际上只是把旧系统搬进了新容器。
我理解的 AI Native,要看产品的核心抽象有没有因为 AI 发生变化,不能只看界面上有没有 AI。
旧系统的核心抽象通常是页面、菜单、表单、按钮、列表、流程。用户通过页面找到对象,通过按钮触发动作,通过表单提交参数,通过列表查看状态。AI Native 的核心抽象应该更接近目标、上下文、状态、工具、证据、计划、反馈和边界。
页面、按钮、表格仍然需要,而且 AI 时代更需要好的 GUI。GUI 的任务会从固定流程入口,扩展到承接对象、状态、影响范围、确认、异常、审计和长期跟踪。ChatUI 负责表达意图和补齐信息,GUI 负责让用户看清对象和后果,后端 API 负责稳定执行能力。
这里就能看出 CLI 和 API 的边界。
API 是产品能力契约。它应该表达业务语义、权限、schema、错误、幂等、dry-run、审计和版本边界。一个好的业务 API,不只让前端能调,也应该让 Agent 能调,让后台任务能调,让测试能调,让审计能追。
CLI 是操作入口。它适合开发者、运维、批处理、本地脚本、调试和临时自动化。CLI 可以很好用,也可以被 Agent 调用,但它不应该替代业务 API。尤其是面向普通员工的长期业务流程,不应该先把 API 包成 CLI,再让 ChatUI 解析自然语言去跑命令。
这样做的问题很具体。类型藏进文本里,权限藏进脚本里,状态藏进终端输出里,错误处理靠模型猜,审计要从聊天记录和命令日志里拼。短期可以 demo,长期很难维护。
把旧 PC 页面直接塞进 App,是移动互联网早期常见的迁移误区。把旧 API 塞进 CLI,再塞进 ChatUI,是 AI 时代的同类误区。两者都只是旧范式在新容器里勉强活着。
更稳的做法,是先把业务能力整理成结构化契约。
如果系统要允许 AI 创建日程,就不应该让模型模拟人去点页面,也不应该主要靠一条 create-calendar CLI。更好的边界是:后端提供结构化工具,说明必填字段、权限、冲突检查、dry-run 输出、确认 token、执行结果和审计记录。ChatUI 可以问「你想约谁、什么时候、主题是什么」,GUI 可以展示冲突、参会人、会议室、影响范围和确认按钮,后端 API 负责执行。
如果系统要让 AI 处理审批,也不应该只给一个聊天框让用户说「帮我批一下」。审批对象、风险项、历史记录、权限、附件、影响范围、确认理由,都应该在结构化界面里让用户看清。AI 可以总结和建议,但高风险动作必须有明确确认和审计。
AI Native 的重点,是让人和 AI 围绕同一套业务对象协作,不必把所有界面都变成对话。
这正是企业 Agent 和普通聊天助手最大的分水岭。聊天助手可以围绕一句话工作,企业 Agent 必须围绕一个有边界的业务对象工作。任务、审批、客户、合同、故障、发布、会议、项目,都承载一组状态、权限、证据、责任和后果。
如果一个 Agent 只知道「有人在群里说了一件事」,它最多能提醒。如果它知道这件事对应哪个任务、当前状态是什么、谁有权限推进、依赖哪些系统、完成标准是什么、失败后怎么回滚,它才有机会稳定代办。AI Native 的关键,是让业务对象变得可理解、可授权、可追踪、可暂停;信息主动推送只是其中一小部分。
这些角色应该分清:
- 人擅长判断目标、承担责任、处理例外和做取舍。
- AI 擅长检索上下文、生成草案、执行重复动作、发现遗漏和把散乱信息整理成候选计划。
- API 提供稳定能力边界。
- GUI 提供可见性和可控性。
- ChatUI 提供意图入口和解释空间。
- CLI 服务开发者和自动化。
这些层分清以后,产品才不会变成一团胶水。
AI 时代做东西,顺序也应该变一下:
- 从用户真实动作和责任边界开始,不要从「要不要做一个 Agent」开始。
- 把业务能力整理成工具契约。
- 按风险决定自动化程度。
- 设计 ChatUI 和 GUI 如何配合。
- 建立评测、日志、回滚和人工接管。
如果只做最后一层,产品会很像 AI。如果前面几层都做了,产品才可能真的 AI Native。
落到开发里的检查项
AI 工作产品的好设计,不是让系统更早发现工作,而是让用户更好地掌握工作。
——《置身钉内》,「用户第四」,第 54 页
这篇文章可以读成一场大厂项目复盘,也可以读成日常开发提醒。
写一个内部工具、浏览器插件、自动化脚本、Agent 能力或管理后台功能时,也会遇到同样的问题,只是规模小一些。
一个按钮会不会写入用户当前浏览器状态。一个缓存会不会跨环境污染。一个自动刷新会不会打断正在看的页面。一个 tooltip 是帮助理解,还是掩盖主文案没写清。一个 Agent 工具调用是低风险 UI 操作,还是会实际改业务数据。一个默认开启的功能是方便,还是把某种偏好强加给所有人。
这些问题都不宏大,但它们背后有同一个世界观:产品到底帮用户掌握工作,还是让系统掌握用户。
这些检查可以直接写进开发前的问题单:
- 先拆原场域动作。再定新入口形态。
- 先看责任流向。再谈效率提升。
- 先算用户成本。再算模型能力。
- 先分风险层级。再决定自动化程度。
- 先做可解释、可关闭、可撤回。再谈主动服务。
- 先确认是否接近根问题。再追求每天可见变化。
这些规则不如「AI 原生」「Agent OS」「统一入口」好听,但它们更接近真实开发。
产品世界观最终会体现在代码里。体现在默认值里,体现在按钮文案里,体现在接口权限里,体现在是否有 dry-run,体现在失败以后有没有回滚,体现在用户能不能关掉某个模块,体现在开发团队愿不愿意停下来承认前提错了。
《置身钉内》写的是一个具体项目。更值得留下的是一个提醒:AI 进入工作流以后,产品、管理和开发不会被简化。相反,它们会更早地碰到彼此。
模型可以让很多事变快,但它不会替团队决定什么是好工作,什么是好管理,什么是好产品。这个判断还是要人来做。
普通人不能成为时代耗材
原文后半段已经不只是产品复盘,而是在算人的账:深夜汇报、身体倒下、团队散掉、价值观被拿来测试服从,最后都落到具体人的身体、情绪、尊严和退路上。AI 办公如果只是让这套管理方式更实时,普通人得到的不会是解放,只会是更细的调用。这里要讨论的,是人在时代和组织里怎么保住判断力,也怎么避免把自己受过的伤再转给别人。
团队散掉不是前线一个人的锅
我记得很清楚的是,去年 11 月 14 日早上很早,我和另一个产品很早去找无招汇报。才 8 点多,秘书也在会议室,在砧板上切新鲜水果榨汁。那天本来汇报一个改动可能比较大的新方案,有些心焦,秘书的在场给我的存在感就格外强烈,她一刀一刀不紧不慢的声音,就像直接切在人的耳膜上。
汇报到一半,秘书把果汁递给无招,后者突然问我们,「xx(另一个产品),幽素,你知道你们最大的问题是什么吗?」
他说,「你们最大的失败是没有团结好团队。人心散了,你们知道吗?」
我哑口无言。
这是我的,我们的失败吗?
——《置身钉内》,「一鼓作气,再而衰,三而竭」,第 72 页
这段的现场感很重。它把一次汇报写成了身体经验:早上、会议室、果汁、砧板、刀声、心焦、突然反问。刺人的地方在于,团队已经在长期救火、改口径、赶包、补洞,最后却被要求为「人心散了」承担主要责任。
团队为什么会散?不一定是某个产品经理没有团结好人。更直接的原因,是团队长期没有稳定的胜仗。每天都在改表面、追热点、补发布会、回应高权重反馈,人的意义感会慢慢被掏空。大家会越来越擅长响应,却越来越不知道自己到底在接近什么。一个团队如果看不见真实用户价值,也看不见自己的判断被尊重,散掉是很自然的结果。
作者为什么会无语?因为这句话把系统性问题反向压回了执行者身上。前线产品能做很多事:组织材料、安抚研发、拆需求、协调设计、整理反馈、提出方案、推动版本。但前线产品通常没有最终方向权,没有停止项目权,没有发布会叙事权,也没有改变组织激励的权力。如果方向、节奏、目标和授权都来自更高层,最后却问执行者「是不是你把团队带散了」,复盘在这里就变成了归责。
无招为什么会觉得这是她的问题?这背后是强管理者常见的视角:团队士气被理解成执行层的管理能力,产品方向、组织节奏和制度设计反而退到背景里。在这种视角里,带团队就是让人继续相信、继续响应、继续往前冲;如果人心散了,就说明中层没有把精神传下去。可现实恰恰相反,一个错误方向上的凝聚力越强,消耗越大。如果团队已经看见前提有问题,还被要求继续燃烧自己去证明方向正确,那么所谓团结就会变成集体自我欺骗。
换作我,当场大概率不会和最高权力直接辩论系统问题。人在那个位置上,先活下来、先避免把局面炸穿,是现实判断。但我会把问题拉回可执行层面:人心散具体表现是什么,哪些人散,散在工作意愿、交付质量、跨组协作还是信任关系上;这个问题由哪些因素造成,哪些是团队内部能改的,哪些需要上层给清晰方向、减少临时改口、停止无效任务、授权砍范围。
如果不得不替这种烂摊子兜底,第一件事是给团队重新找小胜仗,别继续打鸡血。砍掉明显无效的工作,让每个人知道本周只打哪一仗;把临时响应和长期沉淀分账,别让所有人永远在补丁里打转;把上层反馈翻译成可验证任务,别把焦虑原样倒给研发和设计;保护深度工作时间,少开只为了证明在线的会;对上同步真实成本,对下承认真实困难。
这是一种管理能力。能把团队带回来的人,不能只靠口号,要让团队重新相信「今天做的事有用」。没有胜仗,士气只能靠恐惧续命;有胜仗,团队才会自然团结。
身体、情绪和判断力都有边界
写到这里,如果仍然只问「怎样把产品做得更好」,就又回到了旧路上。人还是工具,经验还是燃料,身体还是成本,痛感还是被提炼成方法论的矿石。
——《置身钉内》,「长期第八」,第 94 页
身体不是项目资源,敏感不是可随意磨损的零件,判断力也不是无限透支的账户。
——《置身钉内》,「长期第八」,第 96 页
公司管理里最容易发生的一种错觉,是把人的极限当成资源弹性。项目急,可以多开会;窗口期短,可以晚一点睡;老板关注,可以更快响应;发布会近,可以先熬过去。每一次都像有理由,每一次也都可能真的换来一点进展。
但这套账如果只看项目,不看人,就会变成很残酷的公地问题。组织拿走了更多注意力、身体和情绪稳定性,个体付出的是健康、判断力、亲密关系和长期创造力。短期看,项目吃到了资源;长期看,行业损失的是一批人的信任和手艺。
这里讨论的不是高强度工作本身。重要项目当然会有困难、压力和阶段性冲刺。关键在于,冲刺要换来什么。如果它换来的是技艺、判断、产品突破和可复用能力,人会知道自己为什么累。如果它只换来一轮又一轮解释、补丁、汇报和自证,人的意义感会被慢慢磨掉。
文章里那些人倒下的细节,不能只读成个人身体差、抗压弱,或者项目刚好太忙。它更像一种系统结果:当组织把不清楚的战略包装成战役,把战役包装成使命,再把使命压成每日可见产出,最后承受不确定性的人一定是前线团队。带头人只需要看到战旗还在,执行者却要用工时、睡眠、健康和判断力去填战略空白。
判断一个带头人有没有滑向暴君式管理,要看他如何对待那些暂时比他弱的人:候选人、试用期员工、执行团队、没有采购权的普通用户、无法拒绝默认值的一线员工。人格魅力和理想叙事都不够。理想主义如果只对上负责、对下索取,就会变成包装过的支配欲。
AI 时代尤其要警惕这一点。因为 AI 会让组织更容易想象「人可以更快」。代码可以更快生成,文档可以更快整理,竞品可以更快扫描,方案可以更快堆出来。于是人的空隙也更容易被填满。
但好的 AI 产品不应该把人压得更满。它应该释放人的低价值重复,让人有时间做高价值判断。开发团队也是一样。AI 工具如果只是让团队更快响应上层信息流,却没有更快沉淀能力、更快验证真实问题、更快保护人的注意力,那它只是在给旧管理方式加速。
普通人要拒绝成为时代耗材
人是目的,还是手段。
——《置身钉内》,「长期第八」,第 94 页
这句话很轻,但它是全文最重的问题之一。时代浪潮、组织叙事和管理工具一起压下来时,普通人到底应该怎样活,最终都会回到这个问题:人是目的,还是手段。一个组织嘴上讲 AI、创新、长期,现场却把人的身体、尊严和注意力当成随取随用的材料,它就已经回答了这个问题。一个产品嘴上讲赋能,最后却只让上级更容易催、系统更容易盯、员工更难离场,它也已经回答了这个问题。
它已经超出某一个老板、某一个项目、某一个产品经理的范围。更深处是一套管理基因:用价值观测试服从,用战役叙事替代判断,用奋斗故事遮住成本,用「时代来了」压低普通人的还价能力。
这套管理基因会落到几个很具体的动作里:
- 把价值观变成服从性测试。比如要求员工只用某个工作软件沟通、把私人关系带进组织增长、把「愿不愿意配合」包装成「认不认同组织目标」。价值观到这一步,已经从共同相信的东西,变成判断一个人是否听话的工具。
- 用战役叙事替代管理判断。项目叫战役,加班叫冲锋,复盘叫打仗,但很多时候敌人是谁、目标是什么、判断标准在哪里,反而没人能讲清楚。战役语言最擅长制造紧张感,却很容易掩盖管理者没有想清楚问题。
- 把人写进组织的出厂设置。考勤、日报、周末单休、深夜汇报、临时拉会、随时响应,如果都被当成理所当然,组织其实已经默认「人是可以被连续调用的资源」。这比口号更诚实,因为制度会泄露组织实际相信什么。
钉钉早期很擅长讲这种故事。一句「老大看好你」,可以把漂泊、加班、留在大城市和组织认可绑在一起。它当然能打动人,因为很多人真的没有背景,真的需要机会,也真的需要被看见。

但这类叙事危险的地方也在这里:它把组织承诺包装成个人命运,把上级认可包装成生活意义,把「你要继续撑住」说成「我看好你」。普通人一旦把这种话完全吃进去,就会很难区分自己是在追求成长,还是在替组织燃烧。
大厂经历当然可能有价值。很多人确实从大平台拿到了工资、履历、训练、视野和机会,也确实在复杂项目里学会了系统协作。不能把所有努力都说成无效,也不能把所有回报都说成幻觉。
但需要分清楚的是:回报不等于意义。一个人拿到了回报,不代表他的消耗就有意义;一个项目声势浩大,不代表它真的创造了价值;一个组织给了高薪和头衔,也不代表它有权把人的身体、情绪和判断力当成无限材料。很多时候,人会用平台光环、项目规模和领导认可解释自己的消耗:我这么累,一定是在做重要的事;我牺牲这么多,一定会换来更大的未来;我身体这么差,一定说明这件事值得。
可现实未必如此。很多消耗只是组织惯性、管理焦虑、战略摇摆和表演式忙碌的成本,被转嫁到了具体的人身上。对优秀年轻人来说,最可惜的是把精气神用在无法创造真实价值的系统自证里,把方法论越卷越厚,把身体和精神健康越磨越薄,最后只得到一段很难复用的疲惫。
这张早期广告放在这里,是提醒自己:协作工具从来不是中性的管道。它会告诉用户谁有资格定义努力,谁有资格确认工作,谁的注意力更贵,谁的生活可以被工作打断。
AI 时代还会让这件事更复杂。因为 AI 本来有机会帮助人:替人整理信息,减少重复劳动,降低认知摩擦,把人从低价值事务里解放出来。但同样的 AI,也可以变成更高级的监控摄像头、更细的绩效尺、更快的催办机器。
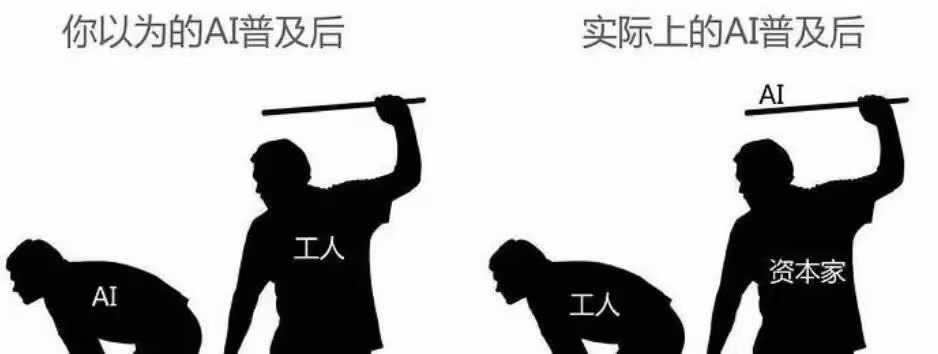
AI 一定会继续进入工作现场,问题已经不在「会不会普及」。更要紧的是:它进入以后,是帮普通人拿回时间、判断和边界,还是帮组织更精确地收集人的时间、判断和边界。
第二张图刺人的地方也在这里。很多人想象里的 AI 普及,是低价值劳动被机器接走,人能把时间留给判断、创造和休息。但在现实组织里,AI 经常先被掌握在拥有流程权、数据权、评价权的人手里。谁能定义指标,谁能调用数据,谁能解释模型结果,谁就更容易先被 AI 放大。
AI 协作工具要回答的,也远远不止「入口在哪里」。入口背后还有更重要的问题:谁拿到上下文,谁能调度任务,谁能记录过程,谁能兜底结果,谁能在系统判断出错时按下暂停。如果入口长在管理确认、催办和绩效统计上,AI 很容易优先服务看见、追踪、归因和问责;如果入口长在知识、任务、上下文和边界保护上,AI 才更可能帮人减少内耗。
钉钉和飞书这类产品的底盘差异,也应该从这里看。一个产品如果从一开始就围绕「管理者如何确认我的人有没有在干活」展开,AI 加进去以后,很自然会变成更聪明的催办和监工。一个产品如果围绕文档、知识库、结构化协作和上下文沉淀展开,AI 至少更有机会先服务「把事理清楚」。后者不天然高尚,但地基会限制 AI 的长法。
在大浪潮里,普通人当然不能假装自己完全自由。很多时候,我们要上班,要领工资,要交房租,要照顾家庭,要在不理想的系统里求生。承认这一点很重要。对普通人来说,现实策略很少是永远硬刚,也很少是永远干净地转身离开。
但承认现实,不等于把现实神圣化。短期服从可以是生存动作,不能变成人格形状;低姿态可以是现实处境,不能变成自我阉割;为了工资忍一段,可以理解,但不能因此相信压榨是对的,不能转过头去压榨更弱的人。
在一个把人当手段的组织里,最理性的短期生存策略往往会变成「你让我做什么我就做什么,多一步都不走」。这未必源于懒,也未必源于没有责任心。系统在训练一种防御姿态:主动发现问题没有奖励,暴露问题可能有惩罚;多做未必加分,少做反而少错;你越有判断,越可能被要求为判断承担额外成本。
如果这种机制长期存在,组织会失去士气,也会失去创造力。一个被训练成只响应指令的人,很难突然在 AI 时代变成主动探索的人;一个长期靠服从保命的团队,也很难突然长出稳定的产品判断。最后工具再先进,现场也只会有更多流程、更密的统计和更快的响应,而不会自动出现更好的工作方式。
我很喜欢这句话:宁可卑微如尘土,不可扭曲成蛆虫。
卑微和扭曲不是一回事。卑微是位置低、资源少、话语权弱,是很多普通人一开始无法选择的处境。扭曲是把伤害合理化,把屈辱转嫁给别人,把自己曾经受过的控制变成管理别人的手段,把「我也没办法」变成伤人的许可证。
普通人在时代浪潮里,至少可以守住几件事:
- 把生存和信念分开。可以暂时做一件不理想的事,但心里要知道它为什么不理想;可以应付一次荒唐要求,但不要把荒唐写成方法论;可以为了生活忍耐,但不要把忍耐变成对压迫的赞美。
- 保住判断力。判断力属于每个在现场承担后果的人,不只属于高管和产品经理。普通员工也要问:这件事是在让我增长能力,还是只是在训练服从;是在解决真实问题,还是在生产可汇报材料;是在让我靠近更好的工作方式,还是在消耗身体换取短期确定性。
- 拿回评价主权。职位、职级、绩效、流量、AI 使用率、仪表盘评分,都是系统的衡量工具,不能等同生命价值本身。一个人不能把自己完全等同于系统给出的分数,也不能因为模型没有记录某种贡献,就相信那种贡献不存在。
- 从执行者变成观察者。短期可以执行命令,但心里要保留一个更高的视角:这个系统在奖励什么,在惩罚什么,在让人失去什么,在把什么伪装成效率。稀缺的人,往往能看懂系统、使用系统,又不被系统完全定义。
- 沉淀可迁移能力。时代会换概念,公司会换方向,产品会换入口,模型会换排名。能带走的,是一组不那么依赖平台的能力:写清楚问题,拆清楚流程,看懂利益关系,用工具验证事实,留下证据,复盘失败,把经验做成作品或方法。
- 给自己留退路。退路不等于马上离职,也不止是钱。退路包括健康、存款、作品集、可信的人际关系、可迁移技能、对行业真实成本的理解,以及知道自己不想变成什么样的人。没有退路的人,最容易被组织改造成只会执行的零件。
- 重建真实关系。算法能统计协作频率,不能生产信任;系统能记录聊天轨迹,不能替代一个真实的人在低谷时接住你。不要让所有关系都变成工作节点、绩效关系和即时通讯里的头像。能在系统之外互相理解、互相托底的小共同体,是普通人抵抗原子化的重要保护层。
- 守住身体。身体有自己的账本,不能当作绩效工具或进度条背后的电池。睡眠、散步、吃饭、运动、具体手艺、真实触感,这些看起来低效的东西,恰恰在提醒一个人:自己首先是有痛觉、有情绪、有感受的生命,而不是系统里一个永动的数据账户。
- 不要成为伤害的中转站。一个人受过强管理,不代表将来可以用同样方式管理别人;一个人被迫熬过夜,不代表有资格要求后来者也熬;一个人吃过亏,不代表可以把亏包装成成长。很多坏系统就是这样延续的:每一层都说自己也只是被迫,每一层都顺手把压力往下传。
还要学会停止。我们总是有太多纠结,最后委屈了自己。事业也好,生活也好,很多不畅快都来自同一种较劲:公司对产品有不合理期待,我们对自己也有不合理期待;组织不愿意承认方向错了,个人也不愿意承认自己已经被消耗得太久。
如果一个事情、一个地方、一个关系长期给不出能量和正反馈,最好的做法未必是继续证明自己,可以先停止参与它的决策。沉没成本本来就不该参与判断。已经投入过时间,不等于还要继续投入;已经忍过一段,不等于还要把忍耐变成身份;已经在一个系统里受过训练,也不等于要把那套训练带到下一段人生里。
人生最贵的东西,未必是某一份工作里的认可。身体、情绪、时间和还能重新选择的能力,往往更难补回来。工作可以给人成就,也可以给人伤口。我们要保护的是长期里的能量、判断、创造力,以及和自己和解以后继续往前走的能力。
时代浪潮下,普通人很难决定浪往哪里打,但可以决定自己不替浪潮发明漂亮话。可以小心,可以低头,可以保存体力,可以慢慢攒能力,可以找机会离开,但不要主动帮系统把人说成耗材,不要把别人的痛感说成不够努力,不要把一套会消耗人的制度包装成先进管理。
做产品和做 Agent 时,也要记住这条底线。工具当然要帮组织提高效率,但效率不能靠吞掉人的边界来实现。AI 当然要进入工作流,但它不能只是把普通人更早、更细、更持续地交给管理系统。
好的工具应该让人更完整,少一点被控制感。好的组织应该让人练成本领,少一点学会扭曲。好的时代也不应该只奖励那些把自己和别人都用坏的人。
最后概括一下
《置身钉内》表面写的是钉钉 ONE,真正留下的是一组更通用的问题:AI 进入组织以后,产品、管理、开发和人的边界会同时被重新分配。
- 产品层。先问清楚谁是客户、谁是用户、谁是承受者,别用一句「用户价值」盖住不同角色之间的利益冲突。
- 组织层。使命过载、方向反复和每日可见变化,会把团队推向奔波。真正的敏捷不是快,而是更短周期地验证更清楚的假设。
- 工程层。AI 会加快实现,也会加快错误前提的扩散。Agent 和 Skill 要帮团队审前提、看风险、留停止线,不只是更快写代码和补流程。
- 工具层。AI Native 不是给旧产品套 Agent 壳,而是重新设计业务对象、权限、上下文、反馈、审计和人工接管。
- 人的层面。技术浪潮会很大,组织压力也会很重。普通人可以适应、学习、低头和求生,但不要主动把人的身体、注意力和尊严说成系统天然可以调用的资源。
AI 办公产品真正要争的,不是谁更会讲入口、谁的模型更强、谁的发布会更大。更难也更重要的是,谁能在真实组织里少一点自欺,少一点耗人,多一点让人重新掌握工作的能力。